Redis: 3 instancje i replikacja Master-Slave cz. 2
21 Sep 2020
database debugging nosql performance redis redis-cluster redis-sentinel replication
Oto druga część rozważań na temat Redisa i Redis Sentinela, w której omówię tą drugą usługę i przedstawię przykładowe konfiguracje oraz wytłumaczenia i rozwiązania problemów, które się pojawią.
W tym wpisie postaram się odpowiedzieć na kilka bardzo ważnych pytań związanych głównie z działaniem usługi Redis Sentinel:
- dlaczego minimalna zalecana ilość Sentineli wynosi trzy?
- dlaczego kworum nie zawsze jest większością jednak w jakich przypadkach może mieć na nią wpływ?
- dlaczego przy dwóch działających Sentinelach przełączanie awaryjne nadal działa?
- dlaczego przy jednym działającym Sentinelu i kworum równym jeden przełączanie awaryjne nie działa?
- dlaczego Sentinele (przy zachowaniu większości) awansują ostatni działający węzeł, który jest w stanie Slave?
- dlaczego Sentinele (przy zachowaniu większości) nie awansuję węzła, który jest w stanie Slave i został uruchomiony jako pierwszy po awarii?
Na ratunek Redis Sentinel #
Przypomnijmy sobie konfigurację początkową, która złożona jest z następujących instancji: 1x Master, 2x Slave, 3x Sentinel. Uruchomiliśmy każdą z nich, replikacja działa poprawnie, wszystko jest OK. Dobrze, a co się stanie jeśli serwer główny ulegnie awarii? Taką sytuację możemy wygenerować na trzy sposoby:
- zatrzymać usługę Redis lub wyłączyć całkowicie serwer nadrzędny, wtedy na serwerach podrzędnych parametr
master_link_statusprzejdzie ze stanuupw standown - w konsoli Redisa wydać polecenie
DEBUG segfault, które wygeneruje błąd segmentacji pamięci i zatrzyma (wyłączy) proces, tutaj także na serwerach podrzędnych parametrmaster_link_statusprzejdzie ze stanuupw standown - w konsoli Redisa wydać polecenie
DEBUG sleep 15, które zasymuluje stan „unreachable” (zawiesi proces), jednak na serwerach podrzędnych parametrmaster_link_statusnadal będzie wskazywał stanup
Jest jeszcze jeden sposób, który polega na wywołaniu skryptu, który doprowadzi do błędu BUSY Redis is busy running a script. You can only call SCRIPT KILL or SHUTDOWN NOSAVE.. Na przykład:
127.0.0.1:6379> eval "for i=0,1000000,1 do redis.call('set', i, i) end" 0
Błąd ten oznacza, że istnieje długo działający skrypt Lua po stronie serwera. Taki skrypt jest wywoływany przez komendy EVAL lub EVALSHA. Długo działający oznacza, że czas wykonywania skryptu przekroczył próg określony w dyrektywie konfiguracyjnej lua-time-limit (domyślnie 5000 ms).
Ponieważ Redis jest jednowątkowy, po przekroczeniu limitu czasu odpowiada komunikatem o błędzie „-BUSY”, aby wskazać, że nadal jest zajęty. Aby zatrzymać taki skrypt, możesz wywołać komendę
SCRIPT KILL, jednak powiedzie się ona tylko wtedy, gdy skrypt nie wykonał żadnych operacji zapisu. Jeśli zapisano dane, jedynym sposobem na jego zatrzymanie jest wyłączenie serwera bez zapisywania zmian za pomocąSHUTDOWN NOSAVE.
Podczas niedostępności serwera głównego, w wyniku polecenia INFO replication pojawi się parametr master_link_down_since_seconds, który odlicza czas, jaki upłynął od utraty komunikacji z serwerem nadrzędnym. Omówimy go jednak później, ponieważ wartość, jaką przyjmuje, mówi o możliwych problemach związanych z przełączaniem awaryjnym. Natomiast dokładne informacje, jakie zwraca komenda INFO, znajdziesz tutaj.
Oczywiście potencjalnych przyczyn niedostępności instancji głównej może być więcej i najczęściej są one związane z awarią całego serwera lub problemami sieciowymi (np. port/interface flapping). Niezależnie od sytuacji, aplikacja łącząca się do serwera nadrzędnego najprawdopodobniej zacznie zwracać błędy, ponieważ HAProxy nie będzie mógł znaleźć serwera pracującego jako Master i odmówi połączenia. Taka sytuacja jest niepożądana i rozwiązaniem jest albo przywrócenie mistrza do działania (zalecany sposób), albo wyzerowanie konfiguracji niedziałających węzłów (co zazwyczaj jest niemożliwe jeśli nie działają i nie ma dostępu do serwerów, na których są uruchomione) i ręczne wypromowanie jednego z serwerów repliki za pomocą polecenia SLAVEOF no one. Widzimy jednak, że takie rozwiązanie wymaga ingerencji administratora i jest mało optymalne. Lepiej, gdyby cała operacja przełączania odbywała się automatycznie — tutaj właśnie z pomocą przychodzi omawiamy już kilkukrotnie Redis Sentinel.
Wykorzystując usługę Redis Sentinel musimy wiedzieć, że ma ona swoje własne komplikacje, dlatego tak ważne jest zrozumienie jak działa wykrywanie usług, które z opcji należy dostroić, szczególnie w przypadku złej infrastruktury lub sieci oraz dlaczego musimy zapewnić odpowiednią liczbę Sentineli. Co równie istotne, architektura replikacji Redis + Redis Sentinel nie gwarantuje zerowej utraty danych (czasami oznacza, że możesz stracić dużo danych, gdy występuje partycja sieciowa), ale może jedynie zagwarantować wysoką dostępność. Podczas awansowania repliki na serwer nadrzędny zawsze istnieje ryzyko utraty wszystkich danych, które zostały zapisane w pamięci lokalnej węzła.
Redis Sentinel to rozwiązanie zapewniające wysoką dostępność (ang. High Availability), które w przypadku problemów automatycznie wykryje punkt awarii i przywróci odpowiednie instancje do trybu stabilnego bez interwencji administratora (przy zapewnieniu odpowiedniej konfiguracji i spełnieniu pewnych warunków). Redis Sentinel działa tylko w replikacji asynchronicznej Master-Slave i nie jest wykorzystywany w przypadku klastra. Jest rozwiązaniem typu hot-standby, w którym serwery podrzędne są replikowane i gotowe do awansu w dowolnym momencie. Może zostać skonfigurowany na dwa sposoby: tylko jako monitor, który nie może wykonać przełączenia awaryjnego, lub jako strażnik, który może rozpocząć przełączanie awaryjne. Jeżeli podczas awarii większość procesów Sentinel nie jest w stanie ze sobą rozmawiać, Sentinel nigdy nie uruchomi przełączania awaryjnego.
Lista najważniejszych zadań, którymi zajmują się Sentinele jest następująca:
- utrzymywanie komunikacji przy użyciu portu 26379 protokołu TCP
- ogłaszanie swojej obecności za pomocą komunikatów Pub/Sub co określony czas (patrz: Pub/Sub)
- stałe monitorowanie kanału __sentinel__:hello wiadomości Pub/Sub w celu wykrywania nowo podłączonych Sentineli lub takich, które są już niedostępne
- utrzymywanie i aktualizowanie (synchronizowanie) parametrów takich jak RunID, adres IP i numeru portu pozostałych Sentineli
- utrzymywanie i aktualizowanie listy obecnie działających Sentineli
- stałe monitorowanie serwerów nadrzędnych, podrzędnych oraz innych Sentineli za pomocą polecenia
PING - stałe monitorowanie stanu mistrza oraz pozostałych Sentineli za pomocą polecenia
INFO, które wysyłane jest do serwerów nadrzędnych i podrzędnych (domyślnie co 10 sekund, odpowiada za to parametrhzwredis.conf) - wykrywanie niedostępności serwera nadrzędnego, gdy nie jest już w stanie poprawnie odpowiedzieć na polecenie
PINGprzez dłużej niż określoną liczbę sekund z rzędu - zarządzanie stanami SDOWN i ODOWN serwera nadrzędnego i stwierdzanie (akceptacja przez kworum) czy jest on faktycznie niedostępny
- wybór lidera, który dokona ew. przełączania awaryjnego
- autoryzacja procesu przełączania awaryjnego większością głosów działających Sentineli
Co ważne, członkowie należący do grupy Sentineli utrzymują trwałe połączenia:
- z serwerami nadrzędnymi w celu ich monitorowania
- z serwerami podrzędnymi, które są wykrywane za pomocą wyjścia polecenia
INFOz serwera nadrzędnego - z pozostałymi Sentinelami, które są wykrywane za pomocą publikowania/subskrybowania wiadomości Pub/Sub
Zapewne zauważyłeś w powyższej liście dwa stany, które definiują stan niedostępności danego węzła (niezależnie od jego roli). Będziemy o nich opowiadać później, jednak już teraz wspomnę, że stan SDOWN (ang. subjectively down) mistrza, oznacza, że jest on niedostępny z perspektywy lokalnej instancji Sentinel, oraz że do oznaczenia takiego stanu nie jest brana pod uwagę decyzja kworum. Natomiast stan ODOWN (ang. objectively down) mistrza oznacza, że jego niedostępność została potwierdzona przez inne Sentinele w grupie (kworum). W źródłach Sentinela obu stanom odpowiadają poniższe makra:
#define SRI_S_DOWN (1<<3) /* Subjectively down (no quorum). */
#define SRI_O_DOWN (1<<4) /* Objectively down (confirmed by others). */
Dobrze, a jakie korzyści płyną ze stosowania Sentineli? Otóż ich wykorzystanie pozwala na rozwiązanie kilku problemów i pozwala na zapewnienie ciekawych mechanizmów. Najważniejszą jest chyba przełączanie awaryjne, dzięki któremu Sentinele są w stanie wykrywać problemy z serwerem nadrzędnym i odpowiednio reagować awansując jedną z replik na nowego mistrza. Drugą ciekawą funkcją jest dostarczanie informacji o serwerze nadrzędnym klientom — Redis Sentinel nie działa jako serwer proxy, jednak pozwala wskazać klientom lokalizację obecnego mistrza. Kolejną istotną rzeczą jest zapobieganie działaniu dwóch lub większej liczby mistrzów w tym samym momencie. Taka sytuacja może wystąpić z powodu awarii spowodowanej brakiem komunikacji między instancjami i brakiem synchronizacji między nimi. Ten przypadek jest również powszechnie nazywany partycją sieciową (ang. Network Partition). Przykładem partycji sieciowej jest sytuacja, gdy dwa węzły nie mogą ze sobą rozmawiać, ale są klienci, którzy mogą rozmawiać z jednym lub obydwoma węzłami.
Na przykład, jeśli używasz Redisa do kolejkowania wiadomości, to w przypadku wystąpienia partycji, klient usunąć klucz z jednej z instancji lub ponownie umieścić usunięty wcześniej klucz. Czyli element bazy może zostać dostarczony kilka razy. Widzisz, że klienci mogę nie zgadzać się co do stanu danych w bazie. Jeśli wymagania mocno odnoszą się do spójności danych a w sytuacji partycji sieciowej pomyślnie zapiszesz klucz A do instancji R1, to klient, który łączy się do replik, spodziewa się, że także zobaczy klucz A. Redis w połączeniu z Sentinelem nawet przy zachowaniu odpowiedniej topologii nie zapewni odpowiedniej konsystencji danych. Przy okazji polecam artykuł Asynchronous replication with failover, który mimo tego, że ma już 7 lat, to w bardzo ciekawy sposób opisuje problemy, które mogą występować w przypadku wykorzystania Sentineli.
Oczywiście nie wszystkie awarie sieci prowadzą do powstania partycji. Jeśli korzystasz z dobrego sprzętu sieciowego w redundantnych konfiguracjach (np. w prawdziwych centrach danych), znacznie zmniejszasz prawdopodobieństwo tego typu sytuacji. Wiele ważnych aplikacji może tolerować utratę danych przez kilka godzin w roku, jednak jeśli nie możesz tolerować utraty danych, Redis + Redis Sentinel (i przez to Redis Cluster) nie są bezpieczne w użyciu i nie gwarantują 100% spójności.
Wykrywanie awarii sieci jest trudne, ponieważ jedyne informacje, jakie możemy uzyskać o stanie innych węzłów, są dostępne właśnie przez sieć i często nie ma różnicy między opóźnieniem a awarią sieci.
Jeżeli serwer podrzędny (lub taki, który powinien być podrzędnym) ma taką samą rolę jak serwer główny, dzięki Sentinelowi, po niewielkim opóźnieniu, jest ponownie konwertowany na rolę Slave. Pozwala to zminimalizować tzw. splity (ang. Split-Brain lub Split-Horizon), czyli zakłócenia, w przypadku których węzły powinny być zgodne co do danej wartości, ale zamiast tego nie zgadzają się i tak naprawdę mają dwie różne. Zapisów (i odczytów) w tym stanie nie powinno się traktować jak w standardowym scenariuszu (bez takich zakłóceń), ponieważ klienci zobaczą różne wyniki w zależności od węzła, z którym rozmawiają. Spójrz na poniższy scenariusz:
- wszystkie instancje przechowują klucz
fooo wartościbar - została wykryta awaria węzła głównego
- awaria została potwierdzona, rozpoczyna się przełączanie awaryjne
- jeden z Sentineli (lider) wysyła komendę
SLAVEOF no onedo jednej z replik - jednak Sentinel zostaje zabity przed otrzymaniem potwierdzenia z repliki
- replika staje się serwerem nadrzędnym
- dochodzi do aktualizacji wartości klucza
foo - stary serwer nadrzędny staje się dostępny
- mamy dwie działające instancje główne o różnych wartościach tego samego klucza
Oczywiście jest to tylko przykład, który jednak pokazuje, że przez pewien czas mogą działać dwa serwery nadrzędne, które mogą mieć różne wartości niektórych danych, jeśli dojdzie do zapisów do któregoś z nich. Jeśli podczas zapisów do aktualnego mistrza wystąpią problemy z siecią, a klienci będą nadal do niego pisać, to jeśli dojdzie do zdegradowania takiej instancji do stanu Slave, wszelkie zapisy wykonane w danym oknie zostaną zniszczone. Narusza to gwarancje trwałości danych, ponieważ w zależności od węzła, z którym komunikowali się klienci, niektórzy z nich utracą swoje zapisy, a inni je zachowają.
Natomiast Sentinel, który uległ awarii, uruchomi się ponownie, to zostanie on uruchomiony ze starą konfiguracją, według której przełączanie nie zostało technicznie zakończone, a Sentinel nigdy nie reklamował nowego mistrza. W takiej sytuacji może dojść do problemów w synchronizacji i uzgodnienia wersji konfiguracji, jednak jeśli konfiguracje Sentineli będą spójne i jeden z Masterów zostanie zdegradowany do instancji Slave, to i tak utraci dane, które przez ten czas zapisał.
Idąc za oficjalną dokumentacją, Redis Sentinel został zaprojektowany do działania w konfiguracji rozproszonej, w której współpracuje wiele procesów Sentinel. Kluczowe jest tutaj słowo rozproszonej, które oznacza, że każdy z Sentineli powinien być rozlokowany w odseparowanej lokalizacji, która umożliwia komunikację z pozostałymi Sentinelami. Często spotyka się konfiguracje, które prezentują uruchomienie Redisa i Sentinela na tym samym hoście. W celu zapewnienia prawdziwego HA nie powinno się uruchamiać Sentinela na tym samym węźle, na którym działa Redis, ponieważ kiedy dany host staje się niedostępny, tracisz jedno i drugie (a stanie się tak, gdy najbardziej będziesz potrzebował niezawodności) co osłabia tylko konfigurację HA.
Zdania na ten temat są oczywiście różne, jednak według mnie, robienie tego w ten sposób jest przykładem złej praktyki i nie zapewni „pełnoprawnej” wysokiej dostępności. Co więcej, jeden z Sentineli powinien znajdować się w całkiem innym centrum danych lub minimum na innej dedykowanej maszynie (generalnie każdy proces Redis i Redis Sentinel powinien być na innym serwerze fizycznym, nawet jeśli są na innych systemach wirtualnych). Oczywiście, wiele przykładów pokazuje uruchomienie obu usług na jednym serwerze (ten artykuł też to robi!), jednak jest to najprawdopodobniej spowodowane zwykłą chęcią zaprezentowania działania replikacji Master-Slave oraz prostotą takiego przekazu. W produkcji takie konfiguracje są w większości bezużyteczne i służą tylko do celów programistycznych i demonstracyjnych.
W rozdziale Master-Slave vs Redis Cluster wspomniałem, że w celu zapewnienia wysokiej dostępności przy wykorzystaniu replikacji Master-Slave, wymaganych jest kilka elementów. Sentinel jest tylko jednym z nich i zajmuje się niezwykle istotną rzeczą: przełączaniem awaryjnym. Oprócz tego umożliwia także wykrywanie instancji nadrzędnej, dzięki czemu klient może wiedzieć, z kim rozmawiać, aby dostać się do takiego serwera oraz synchronizacją konfiguracji między węzłami. Nie konfiguruje natomiast replikacji i nie zapewnia punktu końcowego.
Kworum i znaczenie większości #
Wykorzystanie Redis Sentinela pozwala wykrywać awarie na podstawie decyzji członków kworum, tzn. gdy minimalna liczba członków zgodzi się, że dany mistrz nie działa zgodnie z oczekiwaniami. Podjęta decyzja pozwala rozpocząć proces przełączania awaryjnego w celu awansowania jednego z działających podwładnych na serwer nadrzędny. Oznacza to w konsekwencji, że instancje podrzędne są rekonfigurowane, aby używały nowego mistrza, a aplikacje wiedziały, gdzie obecnie znajduje się nowy serwer nadrzędny o nowym adresie.
Kworum to po prostu nieformalna umowa potrzebna do uznania stanu ODOWN obecnego mistrza. Należy ją trakować jako pewnego rodzaju wyzwalacz wymagany do wyboru nowej instancji głównej i jako głos w sprawie zmiany konfiguracji. Rzeczywiste przełączanie awaryjne wymaga jednak zawsze głosowania większości.
Należy zrozumieć ważną rzecz: wartość kworum. Jest to parametr, który określa minimalną liczbę członków, która uzna serwer nadrzędny za niedostępny i ma ogromny wpływ (zachodzi relacja między kworum a większością) na wynik podjęcia decyzji o autoryzacji procesu przełączania, a mówiąc dokładniej, ma wpływ na ilości Sentineli, która musi zaakceptować proces awansowania nowego mistrza. Możemy mieć pięć Sentineli i kworum ustawione na dwa, co oznacza, że minimum dwoje z pięciu członków musi uznać niedostępność mistrza (zgodzić się co do tego, że jest nieosiągalny) i oznaczyć go jako uszkodzony, jednak wyłonienie nowej instancji głównej (czyli rozpoczęcie procedury przełączania awaryjnego) rozpocznie się dopiero, jeśli większość (czyli minimum trzy) zautoryzuje cały proces, czyli wyrazi na to zgodę. Aby faktycznie dokonać przełączenia awaryjnego, jeden ze strażników musi zostać wybrany na lidera i musi mieć upoważnienie do kontynuowania całego procesu. Dzieje się tak tylko przy głosowaniu większości procesów Sentinel. Jeśli jednak ustawimy kworum na cztery, to po wyzwoleniu przełączenia awaryjnego, Sentinel próbujący wykonać całą operację, musi poprosić o autoryzację minimum czterech członków grupy.
Redis Sentinel pozwala na weryfikację parametru kworum oraz sprawdza, czy wartownicy są w stanie osiągnąć minimalną ilośc wymaganą do przełączenia awaryjnego, a także czy są w stanie zapewnić większość potrzebną do autoryzacji tego procesu. Możemy zweryfikować, czy te warunki są spełnione za pomocą polecenia
SENTINEL ckquorum <label>, które wykonujemy z poziomu konsoli danego Sentinela.
Wyłapanie znaczenia jest niezwykle istotne, ponieważ może się wydawać, że kworum zawsze musi być większością, co nie jest prawdą. Zgodnie z definicją słowa kworum, jest to minimalna liczba członków, niezbędna do podjęcia wiążących decyzji. Kworum jest używane tylko do potwierdzenia stanu ODOWN serwera nadrzędnego, który wyzwala przełączanie awaryjne, jednak aby faktycznie doszło do takiej sytuacji i serwer podrzędny został awansowany, większość członków (więcej zwolenników niż przeciwników) musi wyrazić na to zgodę.
Zwróć uwagę, że ODOWN jest tzw. słabym kworum. Ten stan oznacza jedynie, że w danym przedziale czasowym wystarczająca ilość strażników uznała, że instancja główna nie była osiągalna. Jednak komunikaty mogą być opóźnione, więc nie ma silnych gwarancji, że odpowiednia liczba strażników zgadza się w tym samym czasie co do stanu wyłączenia. Jeśli dany Sentinel uzna, że mistrz nie działa, zacznie wysyłać żądania SENTINEL is-master-down-by-addr do innych wartowników w celu uzyskania odpowiedzi umożliwiających osiągnięcie kworum potrzebnego do oznaczenia mistrza w stanie ODOWN i wyzwolenia przełączenia awaryjnego.
Redis Sentinel ma dwie różne koncepcje „upadku” mistrza. Pierwsza z nich nazywa się subiektywnym wyłączeniem SDOWN (ang. Subjectively Down) i definiuje stan, który jest lokalny dla danej instancji Sentinel. Druga z nich nazywa się stanem obiektywnego wyłączenia ODOWN (ang. Objectively Down) i jest osiągana, gdy wystarczająca liczba Sentineli (co najmniej liczba skonfigurowana jako parametr kworum monitorowanego mistrza) ustawia warunek SDOWN serwera głównego. Co istotne, aby określić mistrza w tym stanie, informacje zwrotne uzyskiwane od innych wartowników (czyli z ich perspektywy) są przesyłane za pomocą komunikatu/komendy SENTINEL is-master-down-by-addr.
Jeśli kworum jest mniejsze niż większość, to autoryzacji dokonuje faktyczna większość, jeśli jest równe większości bądź większe, to autoryzacji dokonuje minimalna ilość członków równa kworum. Jeśli mamy pięć Sentineli i kworum jest ustawione na pięć, to wszyscy strażnicy muszą zgodzić się co do awarii serwera nadrzędnego, a do przełączenia awaryjnego dojdzie jedynie wtedy, kiedy autoryzacji dokonają wszyscy członkowie.
Parametr ten służy głównie do wykrywania awarii serwera głównego, jednak jak sam widzisz, ma wpływ na proces autoryzacji i pozwala tak naprawdę na dostrajanie czułości mechanizmu, który odpowiada za wykrycie i uznanie awarii:
-
jeśli kworum jest ustawione na wartość mniejszą niż większość Sentineli, zwiększa się czułość i Sentinele stają się bardziej wrażliwe na niedostępność mistrza, dzięki czemu przełączanie awaryjne jest uruchamiane gdy niewielka ilość strażników nie może skomunikować się z serwerem główny. Może to jednak powodować przekłamania i niepotrzebne awansowanie instancji podrzędnej na nadrzędną zwłaszcza w przypadku wystąpienia partycji sieciowej
-
jeśli kworum jest ustawione na wartość większą niż większość Sentineli, zmniejsza się czułość, jednak zwiększa gwarancja i pewność, że decyzja o niedostępności jest bardziej miarodajna i właściwa. Pozwala to na zminimalizowanie przypadkowego przełączania. W ten sposób system aktywuje się tylko wtedy, gdy problem rzeczywiście dotyczy węzła głównego, a nie problemu z siecią.
Przy określaniu wartości kworum powinieneś pamiętać o danym środowisku i infrastrukturze. Na przykład mając cztery Redis Sentinele, które rezydują w dwóch rozdzielonych centrach danych ustawienie kworum na trzy przy awarii jednego z DC, może okazać się problematyczne, ponieważ nie uda się przeprowadzić przełączania awaryjnego w przypadku kiedy działać będą tylko dwa z czterech wartowników (wymagany jest jeszcze jeden dodatkowy aby zachować kworum).
Zawsze, gdy kworum jest osiągnięte, większość wszystkich znanych węzłów Sentinel musi być dostępna i osiągalna, aby wybór lidera był możliwy. Następnie lider podejmie wszystkie decyzje dotyczące przywrócenia dostępności usługi w tym:
- wybierze nowego mistrza
- zrekonfiguruje replikę, która zostanie awansowana na nowego mistrza
- rozgłosi nowego mistrza pozostałym węzłom Sentinel
- zrekonfiguruje pozostałe repliki i Sentinele tak, aby widziały nowego mistrza
- zdegraduje starego mistrza, gdy stanie się on ponownie dostępny
Z tego powodu ustawienie tej wartości na równą minimalnej większości (czyli dwa w przypadku trzech Sentineli i trzy w przypadku pięciu) wydaje się optymalnym rozwiązaniem, które jednocześnie pozwala wyeliminować błędną interpretację niedostępności serwera nadrzędnego, dzięki czemu węzły jak i cała replikacja oparta na nich działa przewidywalnie i stabilnie. Wartość kworum nie może być natomiast większa niż ilość działających Sentineli.
Podsumowaniem tego niech będzie poniższa tabela:
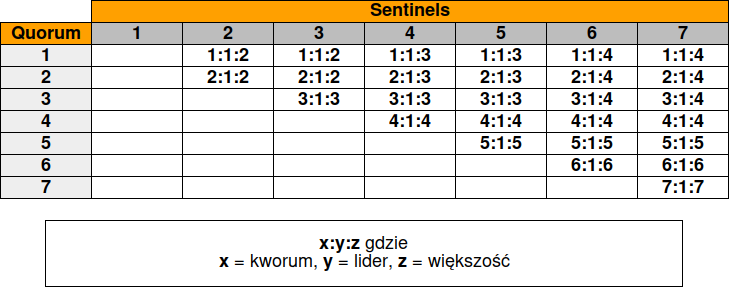
Po jej przeanalizowaniu wnioski są następujące: zawsze jest tylko jeden lider (co jest oczywiste) oraz jeśli wartość kworum jest równa minimalnej większości lub od niej większa, to ma wpływ na wybór lidera i liczbę Sentineli wymaganą do autoryzacji przełączania awaryjnego.
Ile Sentineli potrzebujemy? #
Tym sposobem dochodzimy do kolejnej istotnej kwestii, mianowicie, jaka jest zalecana ilość strażników? Otóż zgodnie z oficjalną dokumentacją, minimalna ich liczba musi być równa trzy, jednak moim zdaniem, idealnie kiedy jest ich więcej. Studiując przykładowe konfiguracje i zalecenia, mogłeś spotkać się ze stwierdzeniem, że ilość Sentineli powinna być zawsze nieparzysta, tj. 3, 5, 7, itd. w celu zachowania większości. Uważam, że nie jest to prawdą, ponieważ aby zaakceptować proces przełączania awaryjnego, wystarczy taka ilość wartowników, z której dopiero będzie można uzyskać nieparzystą większość. Możemy mieć cztery Sentinele, dzięki czemu uzyskamy nieparzystą minimalną większość równą trzy. Może być ich również sześć, dzięki czemu uzyskamy parzystą minimalną większość równą cztery. Natomiast wartością minimalną i graniczną jest liczba dwóch Sentineli (co jednak jest mocno niezalecane), które oczywiście muszą jednocześnie autoryzować cały proces.
Wartość nieparzysta ma jednak ogromne znaczenie dla poprawności działania tzw. algorytmu konsensusu, używanego do rejestrowania przełączeń awaryjnych, który nie znosi liczb parzystych. Odpowiada on za porozumienie członków w sprawie przełączania awaryjnego i jego poprawne działanie jest niezwykle istotne w przypadku awarii. Instancje Sentinel próbują znaleźć konsensus podczas przełączania awaryjnego i tylko nieparzysta liczba wystąpień zapobiegnie większości problemów, przy czym trzy to minimum, aby algorytm ten był skuteczny w przypadku awarii. Dzięki temu jedna z instancji Sentinel może ulec awarii, a przełączenie awaryjne nadal będzie działać, ponieważ (miejmy nadzieję) pozostałe dwie instancje osiągną pewną jednomyślność wymaganą w procesie awansowania do węzła nadrzędnego (zaczekaj jednak na konkretne przykłady, aby zobaczyć, jak system zachowuje się podczas rzeczywistego działania).
Zgodnie z tym, jeśli jest pięć procesów Sentinel, a kworum dla danego wzorca jest ustawione na wartość dwa, to:
- jeśli dwa Sentinele jednocześnie zgodzą się, że Master jest nieosiągalny, jeden z nich spróbuje rozpocząć przełączanie awaryjne
- jednak aby to się stało, muszą być osiągalne co najmniej trzy Sentinele, wtedy dopiero przełączenie awaryjne zostanie autoryzowane i faktycznie się rozpocznie
W praktyce oznacza to, że podczas awarii Sentinel nigdy nie uruchamia przełączania awaryjnego, jeśli większość procesów nie jest w stanie komunikować się ze sobą.
Dokładna informacja dotycząca zaleceń znajduje się w rozdziale Fundamental things to know about Sentinel before deploying oficjalnej dokumentacji. Pozwolę sobie ją zacytować:
1. You need at least three Sentinel instances for a robust deployment.
2. The three Sentinel instances should be placed into computers or virtual machines that are believed to fail in an independent way. So for example different physical servers or Virtual Machines executed on different availability zones.
Podobne uwagi znajdują się w rozdziale Example 1: just two Sentinels, DON’T DO THIS dokumentacji, która opisuje przykład z dwoma działającymi Sentinelami i problemy, jakie taka konfiguracja może powodować.
Widzimy, że ilość Sentineli jest powiązana z wartością kworum, która zależy właśnie od ich liczby. Wiemy też, że kworum to Sentinele, które muszą zgodzić się co do tego, że master jest nieosiągalny, aby oznaczyć go jako uszkodzony i ostatecznie rozpocząć procedurę przełączania awaryjnego (pod warunkiem, że jest możliwe jej uruchomienie). Jednak kworum służy tylko do wykrywania awarii, a nie do przełączania. Aby uruchomić proces przełączenia awaryjnego, jeden z Sentineli musi zostać wybrany na lidera i to on zajmuje się faktycznym przełączaniem. Niemniej jednak, aby mógł to zrobić, musi posiadać upoważnienie do wykonania tego procesu, co stanie się tylko przy głosowaniu większości procesów Sentinel, nie inaczej. Widzimy, że jeśli jeden z węzłów ma być awansowany na węzeł główny, najpierw musi zostać wybrany lider z dostępnych węzłów Sentinel.
Aby uruchomić mechanizm monitorowania i automatycznego przełączania za pomocą Redis Sentinel, wymagane jest uruchomienie takiej ich liczby (w minimalnej ilości trzech, niezależnie od ilości instancji Redis), aby utrzymać większość i zapewnić przynajmniej jedno przełączanie awaryjne.
Inną zaletą takiego rozwiązania jest to, że przełączanie w większości przypadków działa, nawet jeśli nie działają wszystkie instancje, dzięki czemu system posiada pewną tolerancję i odporność na awarie. Posiadanie systemu przełączania awaryjnego, który sam w sobie jest w końcu pojedynczym punktem awarii, jest czymś mocno niepożądanym. Ponadto konfiguracja złożona z minimum trzech instancji Sentinel zmniejsza możliwość pomyłki (fałszywych trafień) w procesie wyboru nowego mistrza. Ważne wspomnienia jest także to, że Sentinel dba o zmianę ustawień konfiguracji master/replika, tak aby wypromowanie i synchronizacja odbywały się we właściwej kolejności, po to, aby nie doszło do uszkodzenia danych — ta praca także zależy od ilości instancji wartowniczych.
Poniższa grafika przedstawia kilka możliwości zachowania się replikacji Master-Slave przy zapewnieniu odpowiedniej liczby Sentineli. Została ograniczona do trzech węzłów, ponieważ jest to wartość minimalna i graniczna, która działa przewidywalnie i zgodnie z zaleceniami. Za jej pomocą chcę pokazać, w jakich dokładnie scenariuszach dojdzie do procesu promowania nowego mistrza a w których nie. Jest ona tak naprawdę potwierdzeniem tego wszystkiego, co powiedziałem w tym rozdziale oraz wstępem do dwóch następnych rozdziałów:
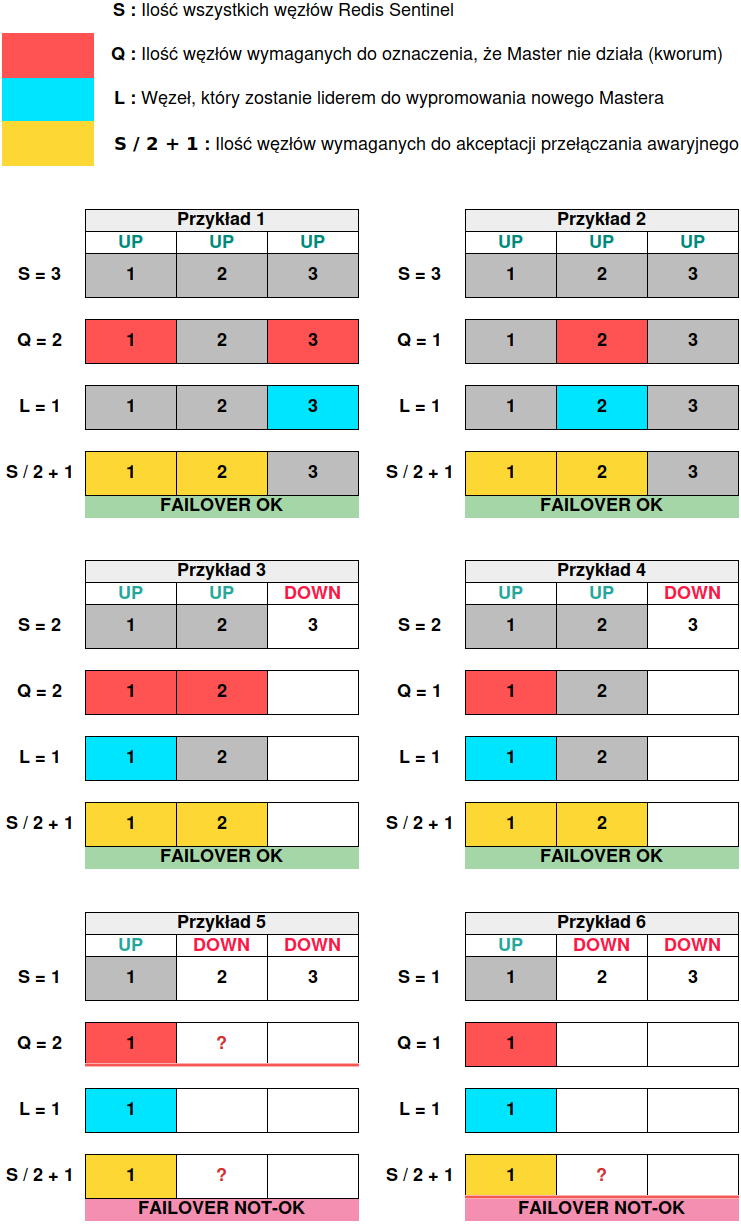
Zapamiętaj dokładnie ostatni przykład. W następnych rozdziałach zobaczysz, że w przypadku jednego działającego wartownika i kworum równym jeden może dojść do awansowania ostatniej działającej repliki do roli Master, ale tylko w przypadku ręcznej ingerencji za pomocą polecenia SENTINEL failover (z wykorzystaniem Sentinela). Działającej, czyli takiej, która była online w momencie awarii mistrza i nie wystąpiła w tym czasie zbyt długa przerwa w replikacji między repliką a instancją nadrzędną. Jeżeli taka replika uległaby awarii i wróciła jako pierwsza, jedyną możliwością awansowania jest wywołanie komendy SLAVEOF no one, oczywiście przy braku spełnionego kworum i większości.
Nie ma jednak róży bez kolców i należy poruszyć niezwykle istotną kwestię jeśli chodzi o działanie Redis Sentinela oraz ręczne mianowanie węzłów za pomocą SLAVEOF no one. Otóż takie działanie jest wysoce niezalecane, o czym wspomina Salvatore Sanfilippo, główny twórca Redisa:
Never use SLAVEOF commands in Redis instances monitored by Sentinel, in a manual way, all the changes must be operated using Sentinel. At this point, every time there is a fail over, Sentinel will make sure that all the configurations are in sync.
Powodem takiego zalecenia jest to, że w przypadku działania Sentineli i promowania ręcznego, Sentinel może nie wiedzieć, że doszło do zmiany konfiguracji bez przełączania awaryjnego. Jeśli chcesz przełączyć instancję główną, musisz uruchomić przełączanie awaryjne za pośrednictwem Sentineli, używając procedury ręcznego przełączania awaryjnego właśnie z ich poziomu. Dzięki temu Sentinel zaktualizuje konfiguracje instancji przy użyciu CONFIG REWRITE i innych środków ostrożności. Oczywiście ogranicza nam to przywrócenie replikacji do działania, ponieważ Sentinel może nie być w stanie awansować danego węzła za pomocą ręcznej procedury. Jednak dobrą praktyką w tym przypadku powinno być wykonanie SENTINEL failover zawsze w pierwszej kolejności.
W przypadku ręcznego awansowania repliki na mistrza za pomocą polecenia SLAVEOF no one stanie się ona z powrotem repliką jeśli stary mistrz zostanie przywrócony do działania oraz jeśli zostaną spełnione dodatkowe warunki, tj. odpowiednia ilość Sentineli, która będzie w stanie przeprowadzić proces przełączania. Dlatego widzisz, że ręczna modyfikacja stanu danego węzła najczęściej jest pozbawiona sensu, może wprowadzić niepotrzebne zamieszanie (przykład dwóch działających instancji głównych) i sprawdza się jedynie w przypadku, w którym wiemy, że nie będziemy w stanie przywrócić serwera nadrzędnego do działania oraz nie mamy odpowiedniej ilości instancji Sentinel, które wykonałyby cały proces automatycznie. Jeśli wykonamy ręczne promowania repliki a Sentinele nadal będą niedostępne, to w przypadku powrotu starego mistrza będziemy mieli dwie instancje nadrzędne. Jeśli wartownicy nadal będą nieosiągalni, to rozwiązaniem tej sytuacji jest ręczne zdegradowanie jednego z nich do roli Slave (najlepiej tego, który nie widnieje jako wartość parametru sentinel monitor).
Problem dwóch instancji #
Chwilę wcześniej napisałem, że dwie instancje Sentinel zapewniają większość. Skoro tak, to dlaczego minimalną zalecaną liczbą są trzy i taka ich ilość zapewnia dopiero wysoką dostępność i odpowiednie monitorowanie węzłów Redis? Wiemy już, że taka ilość jest wymogiem poprawnego działania algorytmu porozumienia. Co więcej, w topologii z trzema węzłami Sentinel możesz pozwolić sobie na wyłączenie tylko jednego z nich, aby proces przełączania nadal działał, co jest niemożliwe w przypadku dwóch instancji, które są minimalną ilością, jaka musi zostać zapewniona, aby mechanizm awansowania w ogóle działał. Kolejno przy pięciu lub sześciu wartownikach maksymalnie dwa mogą zostać wyłączone, aby rozpocząć przełączanie awaryjne, jednak już przy siedmiu maksymalnie trzy węzły mogą ulec awarii. Dostawienie minimum jednego lub dwóch kolejnych Sentineli poprawia dokładność diagnostyki błędów i zwiększa czułość na zmianę stanu mistrza. Ma też ogromny wpływ na autoryzację procesu przełączania i awansowania nowego lidera.
Jeśli masz dwa fizyczne hosty, Sentinel jest przeważnie bezużyteczny, ponieważ gdy jeden z nich ulegnie awarii, większość, zdefiniowana jako S / 2 + 1, nadal wynosi więcej niż jeden i nie ma możliwości, aby drugi Sentinel został wybrany na lidera. Jeśli instancja główna ulegnie awarii, dwa Sentinele nadal działają, więc nastąpi przełączenie awaryjne.
Dlatego trzy Sentinele są ilością minimalną oraz taką, od której rozpoczyna się budowanie grupy Sentineli. Oczywiście nic nie stoi na przeszkodzie, abyś uruchomił parzystą ilość Sentineli, np. równą cztery. W takiej sytuacji także uda się większością głosów potwierdzić proces przełączania, co jest oczywiste i będzie miało miejsce, kiedy trzy z czterech węzłów zatwierdzą całą operację. Widzisz, że tak naprawdę każda liczba równa lub większa od trzech spełnia warunek posiadania większości. Nieparzysta ilość ma jeszcze jeden plus, ponieważ dzięki temu zapewniamy większy zapas Sentineli w przypadku ich awarii.
Posiadanie trzech różnych instancji Sentinel ma o wiele więcej sensu. Jeżeli nie masz możliwości uruchomienia trzech instancji, to możesz rozważyć zainstalowanie trzeciej po stronie klienta (patrz: Example 3: Sentinel in the client boxes) i ustawić kworum na dwa. Fakt, że strażnicy mogą być umieszczeni poza systemem Master-Slave, sprawia, że są one w stanie dokonać decyzji z bardziej obiektywnego punktu widzenia, aby uznać Mistrza za niesprawnego.
W konfiguracji złożonej z dwóch Sentineli dojdzie najprawdopodobniej do przełączenia awaryjnego, ponieważ oba zajmą zgodne stanowisko co do całego procesu. Jednak przy dwóch działających Sentinelach, w przypadku awarii jednego z nich, cały proces się nie powiedzie.
Jedynym powodem uruchomienia grupy z mniej niż trzema Sentinelami jest tak naprawdę wykrywanie usług, co oznacza, że nie używa się go do zarządzania przełączaniem awaryjnym tylko do dostarczania klientom lokalizacji aktualnego serwera nadrzędnego. Jeżeli klienci łączą się bezpośrednio do instancji Redis (z pominięciem np. HAProxy), mogą uzyskiwać adres mistrza właśnie za pośrednictwem usługi Redis Sentinel. Jeśli serwer główny będzie niedostępny, połączenie powinno zostać zerwane przez klienta, po czym klient ponownie połączy się z Sentinelem i otrzyma nowe informacje o mistrzu. Zauważ, że Sentinele śledzą aktualnego mistrza i serwery podrzędne, jednak klienci nie łączą się z serwerem głównym przez nie.
Nawiązując do powyższego, należy nadmienić o jednej istotnej kwestii. Mianowicie, sprawdzając tylko jednego wartownika, nie możesz niezawodnie stwierdzić lokalizacji mistrza, ponieważ istnieje pewne opóźnienie między przełączeniem awaryjnym a strażnikami niebędącymi liderami, więc właściwym rozwiązanie jest uzyskanie informacji wprost od lidera. Tak samo sprawdzając każdy z serwerów wartowniczych, będziesz wiedział, że albo nie możesz komunikować się z mistrzem, albo polegać na decyzji większości, mimo że któryś z Sentineli nie uchwycił jeszcze zmiany.
Co się dzieje gdy działa jeden Sentinel? #
Przejdziemy teraz do sytuacji, która jest niezbędna do zrozumienia przykładów konfiguracji i działania replikacji, które znajdują się w kolejnych rozdziałach.
Przyjmijmy, że nasza początkowa konfiguracja składa się z trzech węzłów, tj. 1x Master i 2x Slave, trzech procesów Sentinel, które działają na tych samych węzłach co instancje Redis oraz kworum równego 2. Jeśli serwer, na którym działa Master ulegnie awarii, tracimy jednocześnie jednego ze strażników. W tej sytuacji wykonany zostanie podobny do poniższego algorytm:
- dwa pozostałe Sentinele wykryją, że serwer nadrzędny jest nieosiągalny ustawiając stan SDOWN, który oznacza, że instancja nie jest już dostępna z punktu widzenia Sentinela, który wykrył niedostępność mistrza
- wyślą żądania SENTINEL is-master-down-by-addr do pozostałych Sentineli
- natomiast do potwierdzenia stanu ODOWN wymagane jest kworum, które w naszej konfiguracji wynosi dwa
- warunek ten zostaje spełniony, ponieważ ilość dostępnych Sentineli jest równa kworum, dlatego kworum powinno zgodzić się na awarię mistrza
- następnie spośród dostępnych Sentineli wybierany jest lider
- aby lider został wybrany, muszą zostać spełnione dwa warunki:
- bezwzględna większość głosujących Sentineli (50% + 1)
- głosy Sentineli zapewniające kworum
- wykonywane jest skanowanie wszystkich podłączonych strażników, aby sprawdzić, czy istnieje przywódca dla określonej epoki
- lider, który wygrał wybory w określonej epoce, może wykonać przełączenie awaryjne pod warunkiem, że mistrz jest w stanie ODOWN
- lider przed rozpoczęciem procesu przełączania awaryjnego wymaga autoryzacji tego procesu u większości Sentineli
- większość jest zapewniona, ponieważ mamy dwóch strażników i oboje akceptują przełączanie
- dzięki temu lider uruchamia przełączanie awaryjne i awansuje jedną z replik na serwer nadrzędny
Po powyższym przełączaniu aktualna konfiguracja to 1x Master, 1x Slave, dwa procesy Sentinel i kworum równe 2. Po pewnej chwili tym razem nowy serwer nadrzędny ulega awarii a razem z nim działający Sentinel, przez co oba stają się niedostępne. Co się dzieje?
- Sentinel, który pozostał w grupie, wykryje, że serwer nadrzędny jest nieosiągalny ustawiając stan SDOWN, który oznacza, że instancja nie jest już dostępna z punktu widzenia Sentinela, który wykrył niedostępność mistrza
- zacznie wysyłać żądanie SENTINEL is-master-down-by-addr do pozostałych Sentineli
- natomiast do potwierdzenia stanu ODOWN wymagane jest kworum, które w naszej konfiguracji wynosi dwa
- warunek nie zostaje spełniony, ponieważ nie mamy wymaganej ilości Sentineli równej kworum, dlatego nigdy nie dojdzie do awansowania nowego mistrza właśnie z tego powodu
Jeżeli chwilę się zastanowisz, to przyjdzie Ci na pewno do głowy, że rozwiązaniem może być zmniejszenie wartości kworum do jeden. Przyjmijmy jednak, że taka wartość była ustawiona od samego początku i pierwszy etap przeszedł bezbłędnie. Rozpocznijmy więc raz jeszcze od ostatniej działającej konfiguracji:
- Sentinel, który pozostał w grupie, wykryje, że serwer nadrzędny jest nieosiągalny ustawiając stan SDOWN, który oznacza, że instancja nie jest już dostępna z punktu widzenia Sentinela, który wykrył niedostępność mistrza
- natomiast do potwierdzenia stanu ODOWN wymagane jest kworum, które w naszej konfiguracji wynosi jeden
- warunek ten zostaje spełniony, ponieważ ilość dostępnych Sentineli jest równa kworum, dlatego kworum powinno zgodzić się na awarię mistrza
- następnie spośród dostępnych Sentineli wybierany jest lider
- aby lider został wybrany, muszą zostać spełnione dwa warunki:
- bezwzględna większość głosujących Sentineli (50% + 1)
- głosy Sentineli zapewniające kworum
- wykonywane jest skanowanie wszystkich podłączonych strażników, aby sprawdzić, czy istnieje przywódca dla określonej epoki
- lider, który wygrał wybory w określonej epoce, może wykonać przełączenie awaryjne pod warunkiem, że mistrz jest w stanie ODOWN
- lider przed rozpoczęciem procesu przełączania awaryjnego wymaga autoryzacji tego procesu u większości Sentineli
- większość jest zapewniona, ponieważ mamy jednego strażnika, który akceptuje przełączanie
Jak myślisz, czy jedyna działająca instancja podrzędna zostanie awansowana na mistrza? Otóż nie, nie zostanie. Jeśli w grupie pozostał jeden Sentinel, to nie może on wybrać lidera, ponieważ nie uzyska większości głosów (zerknij na tabelkę znajdującą się na samym końcu rozdziału wyżej i na wzór S / 2 + 1), nawet mimo głosowania na samego siebie, aby rozpocząć przełączanie awaryjne. Stąd punkty:
- lider, który wygrał wybory w określonej epoce, może wykonać przełączenie awaryjne pod warunkiem, że mistrz jest w stanie ODOWN
- lider przed rozpoczęciem procesu przełączania awaryjnego wymaga autoryzacji tego procesu u większości Sentineli
- większość jest zapewniona, ponieważ mamy jednego strażnika, który akceptuje przełączanie
Albo nigdy się nie wydarzą (brak spełnionych warunków potrzebnych do wybrania lidera) a jeśli wydarzą, to zwrócą błąd, który nie dopuści do wykonania całego procesu przełączania awaryjnego. Rozwiązaniem tego jest dostawienie większej liczby Sentineli. Co istotne i warte wspomnienia, pomijając już to, czy warunki zostały spełnione, czy nie, jeśli dany Sentinel jeszcze nie głosował, to albo zagłosuje na najczęściej wybieranego strażnika, albo na siebie.
Widzisz, że musi zostać zapewniony podstawowy warunek bezstronności, czyli, że ostatni węzeł nie może zostać sędzią we własnej sprawie (zawsze potrzeba dodatkowego głosu), ponieważ możliwość przełączenia awaryjnego bez dodatkowej zgody jeszcze innego członka, byłaby bardzo niebezpieczna i nigdy nie powinniśmy do niej dopuścić. Jeżeli w środowisku mamy trzy Redis Sentinele i jeden z nich ulega awarii, to w przypadku awarii serwera głównego dojdzie do uznania, że jest on niedostępny, ponieważ dwa Sentinele mogą dojść do porozumienia w sprawie awarii i mogą również autoryzować przełączenie awaryjne (co nie znaczy, że w tej sytuacji nie unikniemy problemów). Dlatego tak ważne jest, aby uruchomić minimum trzech wartowników po to, by zawsze dwa węzły z trzech mogły stanowić większość.
Drugim powodem przerwania procesu wyboru lidera i przełączania awaryjnego są działające mechanizmy ochrony danych (zwłaszcza gdy większość Sentineli ulegnie awarii) zapobiegające destrukcyjnym działaniom oraz ewentualnemu ich uszkodzeniu.
Spójrzmy jednak, co dzieje się na samym dole tego procesu. Najpierw ustawiany jest stan SDOWN dla R2:
+sdown master mymaster 192.168.10.20 6379
Następnie potwierdzony musi zostać stan ODOWN, oczywiście zaakceptowany przez kworum:
+odown master mymaster 192.168.10.20 6379 #quorum 1/1
Trwa nowe przełączanie awaryjne, czekające na wybór większości:
+try-failover master mymaster 192.168.10.20 6379
Następuje głosowanie na lidera, w tym wypadku ostatni węzeł głosuje na samego siebie:
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 35
Istotna natomiast jest poniższa informacja, która oznacza, że proces przełączania awaryjnego został przerwany, jeśli dany Sentinel po pewnym czasie nie został liderem, co miało miejsce:
-failover-abort-not-elected master mymaster 192.168.10.20 6379
Po niej następuje powtórzenie procesu:
Next failover delay: I will not start a failover before Sat Sep 19 16:57:05 2020
+new-epoch 36
+try-failover master mymaster 192.168.10.20 6379
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 36
-failover-abort-not-elected master mymaster 192.168.10.20 6379
Pierwszy wpis oznacza, że ostatnia próba przełączenia awaryjnego rozpoczęła się zbyt wcześnie i należy odczekać pewien określony interwał, aby operacja została powtórzona. Wybór lidera może czasami zakończyć się niepowodzeniem w danej rundzie głosowania, gdy nie zostanie osiągnięty konsensus. W takim przypadku nowa próba zostanie podjęta po czasie określonym za pomocą parametru failover-timeout.
Jeśli przełączenie przez wybranego wartownika nie powiedzie się, drugi wartownik będzie czekał na czas przełączenia awaryjnego, a następnie przejmie kontrolę, aby kontynuować przełączanie. Jest to częsty przypadek (zbyt wiele przełączeń), który także blokuje możliwość awansowania nowego mistrza. Zdarza się też, że powyższy błąd jest rzucany przy braku poprawnej komunikacji między węzłami Sentinel, która spowodowana jest niepoprawną wartością parametru bind lub zdublowanym identyfikatorem danego Sentinela. Natomiast najbardziej prawdopodobnym powodem niepowodzenia powyższego procesu jest to, że jeden z Sentineli (w tym wypadku ostatni z nich i jedyny działający) nie może wybrać (co nie znaczy zagłosować) nowego lidera, jeśli dodatkowy z wartowników nie będzie działać.
Proces przełączania awaryjnego wartownika jest maszyną stanową i został zdefiniowany w funkcji sentinelFailoverStateMachine w pliku źródłowym sentinel.c. Podejmuje on następujące kroki:
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_MASTER);
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_replicaof_NOONE:
sentinelFailoverSendreplicaofNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
}
Kluczowe jest wywołanie funkcji sentinelFailoverWaitStart. Za jej pomocą Sentinel zweryfikuje czy jest liderem w danej epoce wywołania przełączania awaryjnego. Jeśli nie jest liderem i nie jest to wymuszona awaria przez ręczne wywołanie SENTINEL failover, zostaje zwrócony błąd, który jednocześnie zostaje zapisany do pliku z logiem:
sentinelEvent(LL_WARNING,"-failover-abort-not-elected",ri,"%@");
Sentinel nie może kontynuować trwającego przełączania awaryjnego, co w konsekwencji prowadzi do wywołania funkcji sentinelAbortFailover. Tę funkcję można wywołać tylko przed potwierdzeniem promowania instancji nadrzędnej do instancji głównej. W przeciwnym razie przełączenia awaryjnego nie można przerwać, a sam proces będzie trwał do momentu, aż zostanie osiągnięty jego koniec (prawdopodobnie przez limit czasu).
Należy pamiętać, że na każdym etapie, który doprowadzi w konsekwencji do awansowania nowego mistrza, tj. weryfikacja kworum, wybór lidera czy zatwierdzenie przełączania, działa wiele różnych mechanizmów (niektóre z nich zostaną zaprezentowane później). Najczęstszym i najprostszym rozwiązaniem podobnych problemów jest zapewnienie minimalnej zalecanej konfiguracji, tak aby mieć pewność, że grupa Sentineli pozostanie silna i odporna na awarie pozostałych członków.
Warunki rozpoczęcia przełączania awaryjnego #
Fakt, że master jest oznaczony jako ODOWN, nie wystarczy, aby rozpocząć proces przełączania awaryjnego. Należy również zdecydować, który z wartowników ma rozpocząć przełączanie awaryjne. Co istotne, strażnik może przyjąć dwie role podczas procesu przełączania:
- rola lidera, dzięki której Sentinel wykonuje przełączenie awaryjne
- rola obserwatora, która oznacza podążanie za procesem przełączania bez wykonywania aktywnych operacji
Obie role zostały zdefiniowane za pomocą flag:
#define SENTINEL_LEADER (1<<17)
#define SENTINEL_OBSERVER (1<<18)
Rola lidera daje ogromną władzę, ponieważ pozwala przeprowadzić proces przełączania awaryjnego. Aby zostać liderem w danej epoce, musi zostać zapewniona większość, czyli większość Sentineli powinna być dostępna. Co więcej, potencjalny lider musi widzieć pozostałych strażników, czyli takich, którzy kiedykolwiek byli widziani od ostatniego zerowania strażnika, i tacy, którzy zgłosili ten sam przypadek co lider z tej samej epoki.
Jednak aby doszło do faktycznego awansowania repliki na mistrza, musi zostać spełnionych kilka warunków (jest to rozszerzona wersja tego co powiedziałem przed chwilą):
- Sentinel będący liderem potrafi wykazać stan SDOWN serwera nadrzędnego
- musi także określić swój stan jako subiektywny przywódca (ang. subjective leader), czyli wybrać sam siebie na lidera
- jego Run ID (unikalny identyfikator) jest najmniejszy według porządku leksykograficznego (sposobu, w jaki słowa są uporządkowane w słowniku, najpierw według pierwszej litery, następnie według drugiej, i tak dalej)
- liczba pozostałych (działających) Sentineli, którzy postrzegają serwer nadrzędny jako nieosiągalny, jest równa kworum
- liczba pozostałych (działających) Sentineli, którzy myślą, że jeden z Sentineli to lider lub tzw. obiektywny przywódca (ang. objective leader), jest równa kworum
- istnieje co najmniej połowa + 1 wszystkich Sentineli zaangażowanych w proces głosowania (którzy są osiągalni i którzy również widzą, że serwer nadrzędny jest niedostępny) na obiektywnego lidera, który dokona ew. przełączania awaryjnego
Jeżeli te warunki zostaną spełnione, to:
- obiektywny lider dokonuje przełączania awaryjnego
- następuje zmiana stanu wybranego serwera podrzędnego w stan mistrza za pomocą polecenia
SLAVEOF NO ONE - następuje zmiana wszystkich węzłów podrzędnych, jeśli tacy istnieją, w węzły podlegające nowemu mistrzowi (czyli są widoczne z poziomu nowego mistrza)
- ten proces odbywa się stopniowo, czyli zmiana odbywa się najpierw dla jednego węzła podrzędnego, a jeżeli proces synchronizacji zostanie zakończony, następuje zmiana stanu kolejnego podwładnego
- stary Master zostaje usunięty z konfiguracji a w jego miejsce wchodzi nowy
Tak naprawdę każdy węzeł Sentinel może zostać liderem. Gdy jeden z Sentineli uzna, że węzeł główny jest subiektywnie w trybie offline, zażąda od innych węzłów Sentinel wybrania siebie jako lidera. Jeśli liczba głosów w wyborach uzyskanych przez dany węzeł Sentinel osiągnie wymagane minimum (czyli według wzoru S / 2 + 1), węzeł taki zostanie wybrany na lidera, w przeciwnym razie wybory zostaną powtórzone.
Natomiast rola obserwatora powoduje, że dany Sentinel widzi stany serwera nadrzędnego, zwłaszcza ODOWN, jednak nigdy nie dokonuje przełączania awaryjnego (czyli nie jest wytypowany na lidera). Sentinel, do którego została przypisana taka rola, nadal może śledzić i aktualizować stan wewnętrzny na podstawie tego, co dzieje się w grupie oraz gdy nastąpi przełączanie awaryjne. Węzeł będący w tym stanie obserwuje stan pozostałych Sentineli, aby zrozumieć, co się dzieje i być na bieżąco z lokalizacją serwera nadrzędnego.
Funkcją odpowiedzialną za weryfikację, czy przełączanie awaryjne jest wymagane, jest sentinelStartFailoverIfNeeded. Weryfikuje ona dodatkowe warunki, które muszą zostać spełnione, aby było możliwe rozpoczęcie tego procesu:
- serwer nadrzędny będzie w stanie ODOWN, dzięki jednomyślności kworum
- w danej chwili nie trwa proces przełączania awaryjnego
- niedawno nie podjęto już próby przełączenia awaryjnego
- zostanie wybrany obiektywny przywódca spośród dostępnych Sentineli należący do kworum
W kodzie Sentinela odpowiada za to poniższy fragment (jest to część wyżej wymienionej funkcji):
/* We can't failover if the master is not in O_DOWN state. */
if (!(master->flags & SRI_O_DOWN)) return 0;
/* Failover already in progress? */
if (master->flags & SRI_FAILOVER_IN_PROGRESS) return 0;
/* Last failover attempt started too little time ago? */
if (mstime() - master->failover_start_time <
master->failover_timeout*2)
Niestety, kroki opisane w tym rozdziale nie są jedynymi, które muszą zostać spełnione, aby proces przełączania awaryjnego zakończył się sukcesem. Etapem, który nie został opisany, jest wybór instancji podrzędnej, która będzie nadawała się do awansowania na nowego mistrza. Kroki potrzebne do dokonania takiego wyboru zostaną opisane w jednym z następnych rozdziałów.
Na koniec odpowiedzmy sobie szybko na dwa pytania, w kontekście procesu awansowania:
- co zyskujemy dzięki wykorzystaniu Sentineli?
- dostępność instancji głównej, ponieważ jeśli ulegnie ona awarii, jej rolę przejmie jedna z instancji podrzędnych
- co zyskujemy dzięki Redis Cluster?
- możliwość automatycznego dzielenia zbioru danych na wiele węzłów
- możliwość kontynuowania operacji, gdy podzbiór węzłów ma awarie lub nie może komunikować się z resztą klastra
Omówienie parametrów konfiguracji #
Podobnie jak w przypadku Redisa, poniżej znajduję się parametry konfiguracyjne z rozbiciem na każdy węzeł:
### S1 ###
bind 192.168.10.10 127.0.0.1
port 26379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
### S2 ###
bind 192.168.10.20 127.0.0.1
port 26379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
### S3 ###
bind 192.168.10.30 127.0.0.1
port 26379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
Przed przystąpieniem do edycji konfiguracji, wykonajmy kilka zadań w celu jej uporządkowania. Katalog /etc/redis mamy już utworzony, dlatego od razu utworzymy kopię głównego pliku konfiguracyjnego:
cp /etc/redis-sentinel.conf /etc/redis/redis-sentinel.conf.orig
Ostatnim krokiem jest posprzątanie w konfiguracji, czyli na podstawie oryginalnego pliku wyfiltrujemy tylko faktyczne dyrektywy z pominięciem komentarzy:
egrep -v '#|^$' /etc/redis/redis-sentinel.conf.orig > /etc/redis-sentinel.conf
bind i port #
Oba parametry mają takie samo znaczenie jak w przypadku Redisa więc nie będę ich raz jeszcze wyjaśniał. Jest natomiast jedna istotna kwestia dotycząca kolejności adresów. Pierwszym adresem musi być adres interfejsu, na którym Redis Sentinel będzie komunikował się z pozostałymi węzłami. Jeżeli pierwszą wartością będzie adres lokalnego interfejsu, to Sentinele nie będą w stanie wymieniać się informacjami, ponieważ proces użyje właśnie tego adresu (pierwszej wartości) przy uruchomieniu, na przykład:
redis 6503 0.3 0.1 142964 2588 ? Ssl 13:30 0:03 /usr/bin/redis-sentinel 127.0.0.1:26379 [sentinel]
W prezentowanej konfiguracji Redis Sentinel będzie nasłuchiwał na dwóch adresach, tj. 192.168.10.x (podane w konfiguracji) i 127.0.0.1 oraz na domyślnym porcie 26379.
W prezentowanej konfiguracji parametr ten ma następujące wartości:
### S1 ###
bind 192.168.10.10 127.0.0.1
port 26379
### S2 ###
bind 192.168.10.20 127.0.0.1
port 26379
### S3 ###
bind 192.168.10.30 127.0.0.1
port 26379
requirepass #
Parametr requirepass ustawia hasło i wymaga od klientów wydania komendy AUTH <PASSWORD> przed przetworzeniem jakichkolwiek innych poleceń. Widzisz, że znaczenie tej dyrektywy jest bardzo podobne jak w przypadku tożsamego parametru ustawianego w konfiguracji Redisa. Co więcej, parametr ten także jest wysyłany w postaci niezaszyfrowanej, więc nie chroni przed atakującym, który ma wystarczający dostęp do sieci, aby przeprowadzić podsłuchiwanie. Mimo tych ograniczeń jest to skuteczna warstwa zabezpieczeń przed oczywistym błędem pozostawiania niezabezpieczonych instancji Sentinel.
Jest to niezwykle ważny parametr, bez którego podłączenie do gniazda danego Sentinela nie wymaga żadnej autoryzacji. Dlatego też bardzo ważne jest zapewnienie dodatkowej warstwy ochrony np. w postaci filtra pakietów, który będzie zezwalał na połączenia do konsoli Sentineli tylko z pozostałych instancji wartowniczych lub zaufanych sieci. W przeciwnym razie każdy może wpiąć się do gniazda, na którym nasłuchuje wartownik i spowodować cykliczny auto-failover, który skutecznie unieruchomi replikację Master-Slave. Można to zrobić za pomocą prostego jednolinijkowca:
while : ; do redis-cli -h 192.168.10.10 -p 26379 SENTINEL failover mymaster ; sleep 0.5 ; done
W prezentowanej konfiguracji parametr ten ma następującą wartość i jest taki sam na każdym węźle:
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
monitor #
Jest to chyba jedna z najważniejszych opcji. Wskazuje ona serwer nadrzędny i mówi, aby Redis Sentinel cyklicznie go monitorował i określał jego stan jako wyłączony tylko wtedy, kiedy wymagana liczba Sentineli, czyli kworum, się na to zgodzi. Parametr ten składa się z kilku wartości. Pierwsza z nich określa nazwę serwera nadrzędnego, dzięki której będziemy mogli się do niego odnosić (będzie występowała kilkukrotnie w konfiguracji) i dzięki której Sentinel będzie mógł automatycznie wykryć lokalizację (adres i port) mistrza. Druga i trzecia wartość wskazują adres IP i numer portu serwera nadrzędnego, który ma być monitorowany. Natomiast wartość ostatnia określa ile serwerów Sentinel musi wyrazić zgodę, aby doszło do uznania, że mistrz nie działa.
Ostatnia z wartości parametru sentinel monitor, tzw. kworum została już dosyć dokładnie wyjaśniona. Przypomnijmy sobie jednak, co oznacza kworum równe 2, czyli wartość wykorzystana w naszej konfiguracji. Mówi ona, że dwa Sentinele muszą jednoznacznie stwierdzić, że serwer nadrzędny jest nieosiągalny i powinien przejść w stan ODOWN. Jeżeli w grupie instancji jest jeden Redis Sentinel, ustawienie kworum na 2 spowoduje, że nigdy nie dojdzie do przepięcia.
Parametr ten musi być taki sam na każdym węźle i musi wskazywać na aktualnego mistrza (czyli serwer, który nie ma w konfiguracji ustawionego parametru replicaof). Co więcej, musi zostać umieszczony na samej górze konfiguracji, ponieważ jak wspomniałem, inne opcje odnoszą się do zdefiniowanej nazwy — parametr monitora musi być umieszczony zwłaszcza przed instrukcją auth-pass, aby uniknąć błędu No such master with the specified name podczas ponownego uruchamiania usługi Redis Sentinel.
Co istotne, parametr ten jest zmieniany automatycznie w zależności od sytuacji, czyli na przykład wtedy, kiedy dojdzie do zmiany serwera nadrzędnego.
W prezentowanej konfiguracji parametr ten ma następujące wartości:
### S1 ###
sentinel monitor mymaster 192.168.10.10 6379 2
### S2 ###
sentinel monitor mymaster 192.168.10.20 6379 2
### S3 ###
sentinel monitor mymaster 192.168.10.30 6379 2
auth-pass #
Jest to druga z kluczowych opcji. Jeśli serwer główny Redis, który ma być monitorowany, ma ustawione hasło (w naszym przypadku ma), należy je wskazać po to, aby instancja Sentinel mogła się uwierzytelniać i administrować procesami Redisa. Jeżeli Sentinel nie będzie w stanie przepinać węzłów, w pierwszej kolejności zweryfikuj czy hasło w obu konfiguracjach na każdym węźle jest takie samo (musi być ono równe z wartościami opcji requirepass i masterauth).
W prezentowanej konfiguracji parametr ten ma następujące wartości i jest taki sam na każdym węźle:
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh
down-after-milliseconds i failover-timeout #
Jeżeli Sentinel nie otrzyma żadnej odpowiedzi na polecenie PING z serwera nadrzędnego w przeciągu określonego czasu zdefiniowanego w parametrze down-after-milliseconds, uzna taki serwer za niedostępny/uszkodzony. Oznacza to, że jeśli dana instancja nie będzie odpowiadała przez 5 sekund, to zostanie sklasyfikowana jako +down (niedostępna) i w konsekwencji zostanie aktywowane głosowanie za pomocą wiadomości +vote w celu wybrania nowego węzła głównego (w obu przypadkach należy zajrzeć do plików dziennika, w którym pojawiają się obie instrukcje). Wartość domyślna to 60000ms (60s, 1min), natomiast w naszej konfiguracji ustawiliśmy ją na 5000ms (5s).
Pingujemy daną instancję za każdym razem, gdy ostatnia otrzymana odpowiedź, tj.
PONGjest starsza niż skonfigurowany czas wdown-after-milliseconds. Jeśli jednak wartość tego parametru jest większa niż 1 sekunda to i takPINGjest wykonywany co sekundę.
Natomiast parametr failover-timeout ustawia limit czasu przełączenia awaryjnego i definiuje on tak naprawdę kilka innych rzeczy (przeczytaj dokumentację parametru w pliku konfiguracyjnym). Wartość domyślna to 180000ms (180s, 3min). Zmienna ta ma wiele różnych zastosowań. Według oficjalnej dokumentacji określa ona:
-
czas potrzebny do ponownego uruchomienia trybu failover po tym, jak poprzednie przełączenie awaryjne zostało już wykonane. Czas ten jest dwukrotnością limitu czasu przełączenia awaryjnego
-
czas przełączenia awaryjnego liczony od momentu, gdy Sentinel wykrył nieprawidłową konfigurację
-
czas potrzebny do anulowania przełączania awaryjnego, które już trwa, ale nie spowodowało żadnej zmiany konfiguracji (
REPLICAOF NO ONEjeszcze nie zostało potwierdzone przez promowaną replikę) -
maksymalny czas oczekiwania w trakcie przełączania awaryjnego, aż wszystkie repliki zostaną ponownie skonfigurowane jako repliki dla nowo wybranego mistrza. Jednak nawet po tym czasie repliki i tak zostaną ponownie skonfigurowane przez Sentinele
W prezentowanej konfiguracji oba parametry mają następujące wartości i jest taki sam na każdym węźle:
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
myid #
Parametr ten nie występuje w zestawie opcji do zmiany, jednak jest on również bardzo ważny. Określa on unikalny identyfikator lub etykietkę (ang. label) każdego węzła Sentinel. Zalecam nie ustawiać tego parametru po to, aby został wygenerowany automatycznie.
Jeżeli w grupie Sentineli występują węzły o takim samym identyfikatorze, mogą pojawić się problemy podczas przełączania awaryjnego. Na przykład może to powodować ignorowanie wszystkich wiadomości w tym tych o automatycznym wykrywaniu awarii i przepinaniu na węzłach o tym samym identyfikatorze.
Parametry dynamiczne #
No właśnie. Musisz wiedzieć, że plik redis-sentinel.conf jest aktualizowany na bieżąco (podobnie jak redis.conf) i znajdują się w nim parametry, które zmieniają się w zależności od statusu danych węzłów. Podglądając sobie aktualny status za pomocą aliasu redis.stats, zobaczysz następujące opcje i ich wartości:
### S1 ###
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
### S2 ###
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
### S3 ###
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
Parametr known-replica (w wersji Redis 5 zastąpił poprzedni parametr known-slave) wskazuje Sentinelowi serwery podrzędne i niezależnie od stanu serwera (Master, Slave) oraz tego czy sama usługa Redisa działa lub nie, te parametry muszą być takie same na każdym węźle, jednak nie może znajdować się tam adres serwera nadrzędnego. Natomiast parametr known-sentinel wskazuje Sentinele, które na każdym węźle muszą być dwoma pozostałymi (nie może być tam adresu lokalnego Sentinela) i podobnie jak w parametrze wyżej jest niezależna od stanu serwera (Master, Slave) oraz statusu usługi Redis.
Konsola #
Podobnie jak w przypadku Redisa, Sentinel umożliwia zarządzanie z poziomu konsoli po podpięciu się do gniazda, na którym nasłuchuje. Poleceń do administracji Sentinelami nie ma zbyt wiele a ich dokładny opis znajdziesz w rozdziale Sentinel commands oficjalnej dokumentacji. Poniżej omówimy tylko najważniejsze z nich.
Aby podłączyć się do konsoli, wydajemy polecenie:
# Bez uwierzytelniania:
redis-cli -h 127.0.0.1 -p 26379
# Z włączonym uwierzytelnianiem:
redis-cli -a $(grep "^requirepass" /etc/redis-sentinel.conf | awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379
Po poprawnym podłączeniu możesz sprawdzić, czy dany węzeł działa:
127.0.0.1:26379> ping
PONG
Każde z poleceń odnoszące się do Redis Sentinela zaczyna się ciągiem SENTINEL. Jednym z ważniejszych jest możliwość sprawdzenia dostępnych mistrzów i ich statusu:
127.0.0.1:26379> SENTINEL masters
Jednak aby wyświetlić informacje tylko o konkretnym mistrzu:
127.0.0.1:26379> SENTINEL master <label>
Natomiast jeśli zależy nam na uzyskaniu adresu i numeru portu aktualnego mistrza:
127.0.0.1:26379> SENTINEL get-master-addr-by-name <label>
1) "192.168.10.10"
2) "6379"
Możemy także wykonać polecenie ROLE, które zwraca informacje o danej instancji:
127.0.0.1:6379> ROLE
1) "slave"
2) "192.168.10.20"
3) (integer) 6379
4) "connected"
5) (integer) 1323988
Kolejne niezwykle istotne polecenie, które pozwala podejrzeć podłączone repliki:
127.0.0.1:26379> SENTINEL replicas <label>
Oraz podłączone pozostałe Sentinele w grupie:
127.0.0.1:26379> SENTINEL sentinels <label>
W przypadku problemów lub potrzeby wykonania procesu przełączania możemy wymusić jego rozpoczęcie za pomocą poniższej komendy, pomijając wszelkie mechanizmy autoryzacyjne:
127.0.0.1:26379> SENTINEL failover <label>
Pozwala ono traktować serwer nadrzędny tak, jakby był nieosiągalny i pomija wszelkie zgody, które w przypadku automatycznego przełączania muszą zostać wydane przez inne Sentinele. Co istotne, po wykonaniu tego polecenia nowa wersja konfiguracji zostanie opublikowana, tak aby inne Sentinele zaktualizowały swoje konfiguracje.
Tryb wiersza poleceń dostarcza możliwość zresetowania ustawień instancji nadrzędnej. Wyzwala on funkcję sentinelResetMaster, która powoduje usunięcie poprzednich stanów instancji głównej, w tym trwającego przełączania awaryjnego, przywrócenie wszystkich możliwych timerów do ustawień domyślnych, a także usunięcie wykrytych replik i Sentineli. Zresetowanie mistrza powoduje także rozłączenie wszystkich połączeń i zestawienie ich na nowo:
127.0.0.1:26379> SENTINEL reset <label>
Domyślnie konfiguracja jest aktualizowana za każdym razem, kiedy dojdzie do zmiany stanu Sentinela. Niekiedy jednak może być przydatne wymuszenie zrzucenia konfiguracji na dysk, np. jeśli utraciliśmy do niej dostęp lub została w jakiś sposób usunięta:
127.0.0.1:26379> SENTINEL flushconfig
Istnieje też możliwość weryfikacji parametru kworum oraz tego, czy Sentinele są w stanie je osiągnąć, aby rozpocząć przełączenie awaryjne, a także zapewnić większość potrzebną do autoryzacji tego procesu:
127.0.0.1:26379> SENTINEL ckquorum <label>
Oczywiście istnieje możliwość dynamicznej zmiany parametrów Sentineli, które ustawiane są w pliku konfiguracyjnym. Jeżeli zajdzie potrzeba zmiany mistrza, którego chcemy monitorować (odpowiada dyrektywie sentinel monitor):
127.0.0.1:26379> SENTINEL MONITOR <name> <ip> <port> <quorum>
Lub gdy wymagane będzie usunięcie obecnego mistrza, który jest monitorowany:
127.0.0.1:26379> SENTINEL REMOVE <name>
Podobnie jeżeli zajdzie potrzeba zmiany pozostałych parametrów danej instancji Redis Sentinel, na przykład:
127.0.0.1:26379> SENTINEL SET mymaster down-after-milliseconds 1000
127.0.0.1:26379> SENTINEL SET mymaster quorum 5
Uruchomienie Sentineli #
Mając tak skonfigurowane Sentinele, przystąpmy do ich uruchomienia:
### S1 ###
sentinel.start
redis.stats
192.168.10.10
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 1
protected-mode yes
replica-read-only yes
sentinel myid ef58a52e53566fde8106b9112ea4b9689023e35e
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
### S2 ###
sentinel.start
redis.stats
192.168.10.20
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 10
protected-mode yes
replica-read-only yes
replicaof 192.168.10.10 6379
sentinel myid f647de705536775591595dfb543a739924ce4364
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
### S3 ###
sentinel.start
redis.stats
192.168.10.30
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 100
protected-mode yes
replica-read-only yes
replicaof 192.168.10.10 6379
sentinel myid c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
Opcje Sentinela zaczynają się od ciągu sentinel jednak dla ogólnej przejrzystości wkleiłem też te obsługiwane z poziomu Redisa.
Dodawanie i usuwanie Sentineli #
Przed przystąpieniem do testowania konfiguracji omówmy jeszcze przypadki dodania nowych Sentineli lub usunięcia starych. Sam proces jest bardzo prosty jednak na tyle ważny, że został opisany w artykule Adding or removing Sentinels oficjalnej dokumentacji.
Mając skonfigurowaną grupę wartowników, dodanie kolejnego jest niezwykle proste i sprowadza się jedynie do ustawienia poniższych parametrów w konfiguracji (czyli tych, które ustawialiśmy dla obecnie działających Sentineli):
bind <ip> 127.0.0.1
port 26379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
Po uruchomieniu takiego węzła w ciągu 10 sekund (wartość parametru hz) zdobędzie on listę pozostałych Sentineli oraz informację o replikach dołączonych do aktualnego mistrza. Jeżeli zajdzie potrzeba dodania kilku Sentineli, to zgodnie z oficjalną dokumentacją, zaleca się dodanie ich jeden po drugim, czekając, aż wszyscy pozostali wartownicy dowiedzą się o pierwszym z nich przed dodaniem następnego.
Usunięcie jednego ze strażników jest trochę bardziej skomplikowane, ponieważ jak wspominaliśmy wcześniej, Sentinele zawsze przechowują informację o sobie jak i pozostałych Sentinelach nawet w przypadku powrotu z awarii czy planowanych restartach. Jest to w pełni zamierzone zachowanie, ponieważ strażnicy powinni być w stanie poprawnie skonfigurować powracającą replikę po awarii, a bez tych informacji nie będą w stanie tego zrobić.
Procedura usunięcia danej instancji jest następująca:
- zatrzymanie procesu Redis Sentinel, który ma zostać odłączony od grupy
- wysłanie polecenia
SENTINEL RESET <label>lubSENTINEL RESET *do wszystkich działających instancji Sentinel, czyli wykonanie tego polecenia na każdym węźle Sentinel - weryfikacja aktualnie aktywnych wartowników za pomocą polecenia
SENTINEL masterslubSENTINEL master <label>na każdym węźle Sentinel
Powyższy przepis sprawi, że usunięty węzeł nie będzie więcej widoczny z poziomu działających Sentineli. Jednak jeśli konfiguracja usuniętego Sentinela nie została zmieniona, to po jego uruchomieniu ponownie zostanie dołączony do grupy — dlatego jeśli chcesz się go pozbyć raz na zawsze, pamiętaj o wyzerowaniu konfiguracji z pliku redis-sentinel.conf.
W przypadku permanentnego usunięcia jednej z replik polecenie SENTINEL RESET jest także wymagane do wykonania, aby działające Sentinele mogły zaktualizować swoje konfiguracje i zapomnieć o usuniętej instancji podrzędnej.
Scenariusz testowy: etap 1 #
Teraz przejdźmy do sedna sprawy, czyli wygenerujemy sobie dwa scenariusze testowe, w tym omówimy problemy, o których wspomniałem na początku tego jak i poprzedniego wpisu.
Na tym etapie sytuacja będzie lekko wyidealizowana, ponieważ pojawiające się problemy będą dotyczyły tylko usługi Redis uruchomionej na każdym z węzłów, natomiast Redis Sentinel uruchomiony także na każdym z nich będzie zawsze działał. Taki scenariusz jest rzadziej spotykany, ponieważ bardzo często oba procesy umieszcza się razem. Jeśli w przypadku awarii pada cały węzeł, na którym uruchomiony jest Redis oraz Redis Sentinel, tracimy obie usługi. Wykonajmy jednak ten etap (pozwoli on wyciągnąć kilka ciekawych wniosków), aby zobaczyć na własne oczy, jak zachowuje się system w przypadku minimalnej wymaganej i zalecanej ilości Sentineli.
Wszystkie węzły działają #
Sytuacja ta ma miejsce kiedy wszystkie węzły są uruchomione i działają poprawnie. W konfiguracji początkowej serwer R1 pełni rolę mistrza natomiast R2 i R3 działają jako repliki.
Mając poprawnie skonfigurowaną replikację Master-Slave oraz usługę Redis Sentinel, możemy przełączać się między węzłami, czyli promować dany węzeł do stanu Master:
127.0.0.1:26379> SENTINEL failover mymaster
OK
Polecenie to jest zalecanym sposobem awansowania, który nie wymaga zgody innych strażników, i powinno być wykonywane zawsze przed wydaniem komendy SLAVEOF no one, która nie daje żadnej gwarancji działania i sprawdza się tylko, jeśli obecny mistrz uległ awarii wraz z Sentinelami, które nie są w stanie zapewnić wymaganego kworum i większości. Co ważne podkreślenia, wydając polecenie SENTINEL failover, Sentinel będzie promował instancję podrzędną do roli mistrza na podstawie parametru replica-priority. Przypomnijmy sobie, że wartość niższa ma pierwszeństwo i oznacza wyższy priorytet. Co więcej, Sentinel rozpatrzy tylko te repliki, które ma ustawione w parametrze sentinel known-replica, i które spełnią kilka dodatkowych warunków (o czym będzie za chwilę):
sentinel known-replica mymaster 192.168.10.20 6379 # R2
sentinel known-replica mymaster 192.168.10.30 6379 # R3
Czyli idąc za tym, Sentinel wybierze jedną z dwóch replik, która ma wyższy priorytet (tutaj: R2, priorytet 10). Zgodnie z tym, w naszej konfiguracji zawsze dojdzie do przepinania R1 (priorytet 1) między R2 (priorytet 10). Następnie Sentinel zaktualizuje parametr sentinel known-replica, który po przepięciu będzie wyglądał tak:
sentinel known-replica mymaster 192.168.10.10 6379 # R1
sentinel known-replica mymaster 192.168.10.30 6379 # R3
Jeżeli Sentinel ponownie przeprowadzi akcję awansowania nowego mistrza, wykona tak naprawdę akcję odwrotną, czyli wybierze węzeł R1 (priorytet 1), który ma wyższy priorytet niż R3 (priorytet 100). Dzięki temu w naszej konfiguracji zawsze dojdzie do przepinania R1 (priorytet 1) między R2 (priorytet 10) i na odwrót, natomiast R3 (priorytet 100) zawsze pozostanie repliką.
Jeżeli zdarzy się sytuacja, że dojdzie do przepięcia z R1 na R2 i Sentinel (bądź administrator) wypromuje z jakiegoś względu raz jeszcze nową instancję do roli Master, a parametry known-replica nie zostaną zaktualizowane w tym czasie, to serwer R3 stanie się mistrzem. Jest to jedyna sytuacja, kiedy R3 może przejąć rolę szefa i ma związek z logicznym ciągiem zdarzeń, ponieważ R3 nadal widnieje w parametrze known-replica zaś drugi węzeł, którego adres IP także znajduje się w parametrze known-replica, jest jeszcze w starej roli Master.
To jest kolejna ważna uwaga: w momencie przepięcia, przez chwilę dwa węzły mają rolę Master, jednak Sentinel natychmiast aktualizuje parametry sentinel monitor i replicaof (oraz parę innych), dzięki którym wiadomo, który z nich przejmie faktycznie rolę serwera nadrzędnego.
R2 nie działa #
W sytuacji kiedy R2 (Slave) ulegnie awarii nie dzieje się nic złego, ponieważ aplikacja nadal może połączyć się do serwera nadrzędnego (za pomocą HAProxy, który go wykrywa). W takiej konfiguracji mamy jednego mistrza (R1) oraz jeden serwer podrzędny (R3).
Dzięki usłudze Sentinel możemy nadal przełączać się między obydwoma działającymi węzłami, ponieważ spełniamy kworum oraz większość wymaganą do autoryzacji przepięcia.
R2 i R3 nie działają #
Jeżeli R2 (Slave) nadal nie działa i awarii ulegnie R3 (Slave) to nadal wszystko będzie działać poprawnie, ponieważ w mamy wciąż działający serwer nadrzędny (R1).
Istotną informacją jest to, że Redis Sentinel nie usuwa ani nie aktualizuje parametrów o węzłach, które nie działają:
redis.stats
192.168.10.10
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 1
replica-read-only no
protected-mode yes
sentinel myid ef58a52e53566fde8106b9112ea4b9689023e35e
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 60000
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
---------------------------------------
# Replication
role:master
connected_slaves:0
master_replid:f469ad2fcbe64467abb0a144087c50bc041088b2=
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:286910
second_repl_offset:-13
repl_backlog_active:14
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28691f
PONG
Widzimy, że nadal mamy dane o znanych replikach. Mimo tego, że aktualnie nie działają to i tak te informacje są potrzebne do ew. przywrócenia węzłów do działania. Podobnie jeśli chodzi o pozostałych strażników. Jest to domyślne zachowanie, w którym strażnicy nigdy nie zapominają już wcześniej widzianych innych strażników, nawet jeśli nie są osiągalni przez długi czas, ponieważ nie chcemy dynamicznie zmieniać większości potrzebnej do autoryzacji przełączania awaryjnego i tworzenia nowej konfiguracji. Jeżeli jedna z replik zostanie naprawiona i uruchomiona, to serwer nadrzędny nadal będzie pełnił rolę nadzorcy (Master), natomiast uruchomiona replika nadal będzie serwerem podrzędnym.
Żaden z węzłów nie działa #
W tej sytuacji żaden z węzłów nie jest uruchomiony, a tryb replikacji nie jest zestawiony. HAProxy nie może połączyć się do mistrza, czego konsekwencją jest to, że aplikacja również nie działa (np. nie działa mechanizm logowania do aplikacji).
Co zrobić w takiej sytuacji? W pierwszej kolejności najlepiej jest przywrócić do działania serwer nadrzędny, aby uniknąć ew. utraty danych. Jeśli jednak nie jest to możliwe, staramy się uruchomić jedną z replik. Jeżeli R2 lub R3 zostaną uruchomione, to i tak będą one w stanie Slave.
R2 staje się online #
W sytuacji kiedy jedna z replik stanie się dostępna, natomiast Master nadal nie został uruchomiony (przyjmijmy, że drugi Slave także nie jest dostępny), musimy awansować działającą replikę (w tym przykładzie niech będzie to R2) ręcznie na instancję główną. Powinieneś teraz powiedzieć: hola, hola. Przecież wyraźnie powiedziałeś, że problemy z pojedynczym węzłem pojawiają się wtedy, gdy działa jeden Redis Sentinel, a nie Redis. W tym przykładzie mamy przecież trzy działające Sentinele więc dlaczego nie są one w stanie wybrać nowego mistrza?
Już odpowiadam. Podejrzyjmy najpierw status węzła R2:
redis.stats
192.168.10.20
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 10
protected-mode yes
replica-read-only yes
replicaof 192.168.10.10 6379
sentinel myid f647de705536775591595dfb543a739924ce4364
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
---------------------------------------
# Replication
role:slave
master_host:192.168.10.10
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:158344
master_link_down_since_seconds:1600538998
slave_priority:10
slave_read_only:1
connected_slaves:0
master_replid:964c72f36cb33e1d8c7b88c9d9f3e01da375aa64
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:158344
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
PONG
Zapamiętaj wartość parametru master_link_down_since_seconds, ponieważ omówimy go za chwilę. Najpierw jednak kolejny raz odniesiemy się do statusów:
+reboot slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
-sdown slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
+new-epoch 6355
+try-failover master mymaster 192.168.10.10 6379
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
ef58a52e53566fde8106b9112ea4b9689023e35e voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
647de705536775591595dfb543a739924ce4364 voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
+elected-leader master mymaster 192.168.10.10 6379
+failover-state-select-slave master mymaster 192.168.10.10 6379
-failover-abort-no-good-slave master mymaster 192.168.10.10 6379
Next failover delay: I will not start a failover before Mon Sep 21 10:45:36 2020
Pierwsze dwa wpisy oznaczają, że doszło do ponownego uruchomienia węzła R2, oraz że nie jest on już w stanie SDOWN:
+reboot slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
-sdown slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
Generalnie w przypadku niedostępności serwerów podrzędnych, w dzienniku pojawią się podobne wpisy do poniższych:
+sdown slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
+sdown slave 192.168.10.30:6379 192.168.10.30 6379 @ mymaster 192.168.10.10 6379
Wróćmy jednak do problemu. W pliku z logiem Sentinela widzimy, że dochodzi do głosowania na lidera, który dokona przełączania awaryjnego:
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
ef58a52e53566fde8106b9112ea4b9689023e35e voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
647de705536775591595dfb543a739924ce4364 voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 6355
Oba wpisy mówią o tym, który z Sentineli zagłosował za danym węzłem o określonym identyfikatorze. W tym przypadku pozostałe Sentinele zagłosowały za S2, który zresztą zagłosował sam na siebie. Przypomnijmy sobie, co powiedzieliśmy wcześniej, że nie można być (jedynym) sędzią we własnej sprawie (co nie znaczy, że nie można na siebie zagłosować) jednak w tym przypadku nie jest to problemem, ponieważ są inne działające Sentinele w grupie, które potwierdzają cały proces.
Węzeł S2 wygrał wybory dla określonej epoki, zostało to zatwierdzone przez większość Sentineli i stał się liderem, dzięki czemu może wykonać przełączenie awaryjne:
+elected-leader master mymaster 192.168.10.10 6379
W powyższym wpisie widzisz adres niedziałającego, ale jeszcze obecnego mistrza. Nie jest to żaden błąd ani pomyłka. W dzienniku możesz spotkać adres mistrza (to samo dla failover-state-select-slave), który informuje tylko o urządzeniu głównym, ponieważ przełączenie awaryjne nie zostało zakończone, więc nadal będzie to stary adres i port. Po pomyślnym zakończeniu przełączania awaryjnego zostanie zastąpiony nowym adresem IP i portem awansowanej instancji głównej.
Proces przełączania jest kontynuowany. Aby zrozumieć kolejny wpis, musimy ponownie odnieść się do maszyny stanów:
+failover-state-select-slave master mymaster 192.168.10.10 6379
Wpis ten oznacza przejście do stanu SENTINEL_FAILOVER_STATE_SELECT_SLAVE i wyzwala funkcję sentinelFailoverSelectSlave, która odpowiada za wybór serwera podrzędnego do awansu. Funkcja ta uruchamia metodę sentinelSelectSlave odpowiedzialną za sprawdzenie dostępnych Sentineli. Wartownik używa polecenia INFO, aby znaleźć serwery podrzędne, których może użyć do przełączenia awaryjnego.
Dochodzimy teraz do niezwykle interesującej i istotnej rzeczy, która tłumaczy i pozwala zrozumieć zachowanie opisane w przykładach. Tak naprawdę, aby przeprowadzić proces awansowania, muszą zostać spełnione poniższe warunki. Pozwalają one odrzucić węzły podrzędne, które nie nadają się do promowania:
- Odrzucenie wszystkich replik będących aktualnie lub w ostatnim czasie (np. po awarii) w jednym z poniższych stanów:
- SDOWN
- ODOWN
- wniosek z tego taki, że aby replika została awansowana na mistrza, musi działać zwłaszcza w momencie, kiedy mistrz staje się nieosiągalny
- jeżeli nie działa i ponownie zostanie uruchomiona, to w przypadku niedostępności serwera nadrzędnego, nie będzie w stanie ponownie się z nim połączyć, co w konsekwencji spowoduje brak możliwości awansowania jej do roli Master, głównie ze względu na zbyt długi czas braku połączenia między nimi
- Odrzucenie wszystkich niepodłączonych replik oraz takich, których przerwa w replikacji (czyli czas odłączenia od mistrza) zdefiniowana w
master_link_down_timejest większa niż zdefiniowany maksymalny czas wmax_master_down_timedla takiej przerwy- niepodłączona replika jest zawsze w stanie DISCONNECTED (co ciekawe, wszystkie instancje startują zawsze w tym stanie), oznacza to jedynie, że replika musi działać (być podłączona)
- jeśli mistrz jest w stanie SDOWN (czyli najprawdopodobniej nie działa) to dodaj czas niedostępności do 10 * down_after_period, gdzie zmienna ta może być modyfikowana za pomocą
down-after-millisecondsw pliku konfiguracyjnym - ponadto jeśli serwer podrzędny miał rolę Master, ale został zdegradowany, to nie zostanie dodany do tablicy poprawnych węzłów
- wniosek z tego taki, że Master musi działać bądź być widoczny z poziomu danej repliki, co oznacza, że czas przestoju nie może być za długi, aby dana replika mogła zostać awansowana do roli mistrza
- chodzi również o rozwiązanie kwestii zaufania, tzn. jeśli serwer nadrzędny staje się niedostępny, to czy możemy ufać replice po odłączeniu mistrza, która może mieć nieaktualne dane spowodowane opóźnieniem w ich synchronizacji
- Odrzucenie wszystkich replik, które nie odpowiedziały na
PINGw ciągu ostatnich 5 sekund- przypomnijmy sobie, że pingujemy instancje za każdym razem, gdy ostatnia otrzymana odpowiedź, tj.
PONGjest starsza niż skonfigurowany czas wdown-after-milliseconds - jeśli jednak wartość tego parametru jest większa niż sekunda to i tak
PINGjest wykonywany co sekundę - mówiąc ogólnie, odpowiedź na
PINGnie może być większa niżinfo_validity_time
- przypomnijmy sobie, że pingujemy instancje za każdym razem, gdy ostatnia otrzymana odpowiedź, tj.
- Odrzucenie wszystkich replik, dla których czas otrzymania odpowiedzi na polecenie
INFOnie jest większy niż 3-krotność okresu odświeżaniaINFO- tak naprawdę
info_refreshnie może być dłuższy niż 5 sekund, gdy Master jest w stanie SDOWN - jeśli mistrz jest w stanie SDOWN, co sekundę otrzymujemy
INFOdla replik. W przeciwnym razie otrzymujemy to ze zwykłym okresem, więc musimy liczyć się z większym czasem dostarczenia (opóźnieniem) odpowiedzi - mówiąc ogólnie, odpowiedź na
INFOnie może być większa niżinfo_validity_time
- tak naprawdę
- Odrzucenie wszystkich replik z priorytetem równym zero
Natomiast fragment kodu, który odpowiada za ten algorytm, jest następujący:
if (master->flags & SRI_S_DOWN)
max_master_down_time += mstime() - master->s_down_since_time;
max_master_down_time += master->down_after_period * 10;
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN)) continue;
if (slave->link->disconnected) continue;
if (mstime() - slave->link->last_avail_time > SENTINEL_PING_PERIOD*5) continue;
if (slave->slave_priority == 0) continue;
/* If the master is in SDOWN state we get INFO for slaves every second.
* Otherwise we get it with the usual period so we need to account for
* a larger delay. */
if (master->flags & SRI_S_DOWN)
info_validity_time = SENTINEL_PING_PERIOD*5;
else
info_validity_time = SENTINEL_INFO_PERIOD*3;
if (mstime() - slave->info_refresh > info_validity_time) continue;
if (slave->master_link_down_time > max_master_down_time) continue;
instance[instances++] = slave;
}
Co istotne, zasady te są stosowane i sprawdzane pojedynczo po wybraniu lidera i jeśli którakolwiek z nich dotyczy niewolnika i zostanie spełniona, taka replika nie zostanie dodana do listy kandydatów do awansu.
Spośród wszystkich serwerów podrzędnych, które przeszły przez powyższy proces weryfikacji i spełniają odpowiednie warunki, wybierany jest jeden, w następującej kolejności:
- wyższy priorytet
- większe przesunięcie przetwarzania replikacji
- leksykograficznie mniejszy RunID
- jeśli RunID jest taki sam, wybierany jest Slave, który przetworzył więcej poleceń (danych) z mistrzem
Metoda sentinelSelectSlave zwraca wskaźnik do wybranej instancji podrzędnej, w przeciwnym razie zwraca NULL, jeśli nie znaleziono odpowiedniej repliki. W naszym przykładzie niestety proces awansu się nie powiedzie. W związku z tym zostanie wyzwolony komunikat -failover-abort-no-good-slave, a następnie zapisany do dziennika:
if (slave == NULL) {
sentinelEvent(LL_WARNING,"-failover-abort-no-good-slave",ri,"%@");
sentinelAbortFailover(ri);
}
Oznacza on, że nie można wybrać odpowiednio dobrej repliki, która stałaby się mistrzem. Algorytmy Sentinela spróbują wykonać ponowne przełączanie za jakiś czas, ale prawdopodobnie taki stan się nie zmieni i automat stanowy w ogóle przerwie przełączanie awaryjne w tym przypadku. Dzieje się tak prawdopodobnie dlatego, że serwer podrzędny utracił połączenie z mistrzem i przerwa w replikacji jest zbyt długa. W wyniku tego żaden z serwerów podrzędnych nie jest wystarczająco dobry, aby być nowym mistrzem, w związku z czym widzimy błąd -failover-abort-no-good-slave w dzienniku Sentinela po awarii mistrza. Takie zachowanie jest mocno powiązane z replikacją, która jest asynchroniczna. Dlatego w przypadku awarii brak możliwości zapisu w rzeczywistości oznacza, że replika jest odłączona lub nie wysyła nam asynchronicznych potwierdzeń przez więcej niż określoną maksymalną liczbę sekund.
W tym przykładzie, czyli gdzie R2 staje się online, głównym powodem problemów jest to, że serwer nadrzędny R1 nie działa, przez co połączenie między nim a repliką jest zerwane przez zbyt długi okres czasu. Ważne jest także to, że R2 także wcześniej nie działał, przez co nadal może mieć włączone flagi
SRI_S_DOWN|SRI_O_DOWN(co wydaje się trochę dziwne, ponieważ powinien je utracić podczas powrotu).
Jest jeszcze jedna niezwykle istotna kwestia, mianowicie parametr master_link_down_since_seconds, który jak zobaczysz, ma niebotycznie dużą wartość, nawet jeśli urządzenie główne było wyłączone tylko przez kilka sekund. Zgodnie z definicją, parametr ten określa, jak długo (w sekundach!) trwa przerwa w komunikacji między urządzeniem głównym a podrzędnym (czyli jak długo nie mogą się skomunikować). Taka duża wartość pojawia się wtedy, kiedy serwer nadrzędny nie działa, zaś serwer podrzędny wrócił ze stanu awarii (czyli przeszedł ze stanu offline do online). Nie jest to błąd, tylko świadome zachowanie, które jest kolejną warstwą chroniącą przed wykonaniem procesu przełączania. Wartość tego parametru jest natomiast liczona poprawnie, kiedy serwer podrzędny nadal działa zaś mistrz uległ awarii i stał się niedostępny.
Niekiedy podobne problemy można zaobserwować w przypadku takiego scenariusza:
- R1 ma rolę Master
- R2 ma rolę Slave
- R1 staje się niedostępny, Sentinel działa poprawnie i promuje R2 do roli Master
- R1 staje się dostępny i wraca ze starym statusem (Master)
- Sentinel degraduje R1 do roli Slave
- R2 staje się niedostępny
- Sentinel nie promuje R1 do roli Master
Oczywiście powodów nieawansowania repliki może być wiele, np. jeśli Sentinele nie są w stanie ze sobą rozmawiać (można spróbować wyłączyć tryb protected mode) lub kiedy wykorzystujesz specyficzne środowisko (zerknij na rozdział Sentinel, Docker, NAT, and possible issues). Spotkałem się też z sugestią, aby ustawić parametr replica-read-only no, jednak idąc według wyżej wymienionych punktów, raczej nie ma możliwości, aby był on faktycznym rozwiązaniem. Natomiast bardzo często powodem może być działanie mechanizmu, który weryfikuje czas niedostępności serwera podrzędnego (o czym już wspomniałem). Jeśli będzie on odłączony od mistrza przez określony czas, wówczas Slave jest uważany za nieodpowiedni do wyboru na rolę Master. Błahą przyczyną może być też ustawienie priorytetu na zero lub błędnie ustawione hasło dlatego warto zweryfikować także te ustawienia. Jedynym znanym mi rozwiązaniem, które działa, jest albo uruchomienie starego mistrza, albo ręczne wypromowanie repliki za pomocą komendy SLAVEOF no one (pamiętajmy jednak o pewnych ograniczeniach takiego promowania oraz o tym, co się stanie jeśli stary mistrz stanie się dostępny, a wymagana ilość strażników nadal będzie offline).
Gdyby udało się znaleźć serwer podrzędny, proces przeszedłby dalej i odłożył w dzienniku komunikat +failover-state-send-slaveof-noone, czyli wykonał polecenie SLAVEOF no one, które wyłączy replikację w danej replice, zmieniając instancję w serwer nadrzędny.
Pamiętaj, że wiele informacji o parametrach Sentineli możemy uzyskać za pomocą komendy sentinel sentinels, która okazuje się bardzo pomocna podczas debugowania problemów. Wynik tego polecenia może wyglądać tak jak poniżej i różni się w zależności od tego, na której instancji Sentinel zostanie ono uruchomione:
127.0.0.1:26379> SENTINEL sentinels mymaster
1) 1) "name"
2) "c8e2591af9d8437bdafd78ccdc6c5b9f618613d6"
3) "ip"
4) "192.168.10.30"
5) "port"
6) "26379"
7) "runid"
8) "c8e2591af9d8437bdafd78ccdc6c5b9f618613d6"
9) "flags"
10) "sentinel,master_down"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "360"
19) "last-ping-reply"
20) "360"
21) "down-after-milliseconds"
22) "5000"
23) "last-hello-message"
24) "20"
25) "voted-leader"
26) "ef58a52e53566fde8106b9112ea4b9689023e35e"
27) "voted-leader-epoch"
28) "5885"
2) 1) "name"
2) "f647de705536775591595dfb543a739924ce4364"
3) "ip"
4) "192.168.10.20"
5) "port"
6) "26379"
7) "runid"
8) "f647de705536775591595dfb543a739924ce4364"
9) "flags"
10) "sentinel,master_down"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "855"
19) "last-ping-reply"
20) "855"
21) "down-after-milliseconds"
22) "5000"
23) "last-hello-message"
24) "1412"
25) "voted-leader"
26) "ef58a52e53566fde8106b9112ea4b9689023e35e"
27) "voted-leader-epoch"
28) "5885"
Przypomnijmy jeszcze, że jednym z najistotniejszych poleceń, jakie przydają się w przypadku szerszej analizy tego co się dzieje, jest komenda MONITOR uruchomiona z poziomu konsoli danej instancji Redis:
127.0.0.1:6379> MONITOR
OK
1600927132.287841 [0 192.168.10.20:38831] "INFO"
1600927132.287905 [0 192.168.10.20:38831] "PING"
1600927132.478911 [0 192.168.10.30:52278] "INFO"
1600927132.479005 [0 192.168.10.30:52278] "PING"
1600927144.922003 [0 127.0.0.1:47646] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.922321 [0 127.0.0.1:47646] "info" "replication"
1600927144.931165 [0 127.0.0.1:47648] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.931465 [0 127.0.0.1:47648] "info" "replication"
1600927144.941100 [0 127.0.0.1:47650] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.941373 [0 127.0.0.1:47650] "info" "replication"
[...]
Więc w przypadku analizy scenariuszy testowych, zachęcam do podejrzenia, co się dzieje pod spodem całego procesu. Zweryfikujmy jeszcze rozwiązanie ręczne, które już znamy. Przełączmy w takim razie działającą replikę w serwer nadrzędny:
127.0.0.1:6379> SLAVEOF no one
OK
127.0.0.1:6379>
Po tej zmianie zweryfikujmy ponownie jej status:
redis.stats
192.168.10.20
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 10
replica-read-only no
protected-mode yes
sentinel myid f647de705536775591595dfb543a739924ce4364
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.20 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 60000
sentinel known-replica mymaster 192.168.10.10 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
---------------------------------------
# Replication
role:master
connected_slaves:0
master_replid:ddbeacc51dfdeb461f268f4fce58e789cb145157
master_replid2:f469ad2fcbe64467abb0a144087c50bc041088b2
master_repl_offset:26427
second_repl_offset:26428
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
PONG
Co się zmieniło?
- z konfiguracji nowego mistrza został usunięty parametr
replicaof - sentinel monitor przeskoczył na nowego mistrza (192.168.10.10 na 192.168.10.20)
- zaktualizowane zostały instancje będące replikami (192.168.10.20 i 192.168.10.30 na 192.168.10.10 i 192.168.10.30)
- zaktualizowane zostały pliki konfiguracyjne wszystkich działających strażników
Ten przykład pokazuje spory problem w przypadku, kiedy chcemy zapewnić ciągłość zapisów, zwłaszcza tych, które są tymczasowe. Mając replikę, która wróciła z awarii, nie będzie ona przyjmowała zapisów, więc np. logowanie do panelu użytkownika, które wykorzystuje sesje, może nie działać.
Czy w takim razie istnieją możliwe rozwiązania tych problemów? Otóż tak. Jednym z nich może być wyłączenie trybu tylko do odczytu poprzez ustawienie parametru replica-read-only no, który spowoduje, że instancja podrzędna zacznie przyjmować zapisy. Pamiętaj jednak, że zapisy do urządzenia podrzędnego nadają się dla danych efemerycznych i będą odrzucane, gdy urządzenie podrzędne zostanie ponownie zsynchronizowane z mistrzem lub ponownie uruchomione (jeśli nie zapisujemy danych do pliku). Może to powodować mało przewidywalne zachowania a dwa, wymaga innego podejścia w przypadku wykorzystania load balancera takiego jak HAProxy.
Ponadto jednym z lepszych rozwiązań jest wykorzystanie KeyDB Active-Replica lub Multi-Master, które zachowują się stabilnie w warunkach produkcyjnych. Można też wykorzystać kilka instancji nadrzędnych i rozkładać ruch z poziomu aplikacji.
Przygotowałem poprawkę, która rozwiązuje problem nieawansowania repliki w przypadku zbyt dużego interwału przesunięcia replikacji i ogromnej wartości parametru odpowiedzialnego za maksymalny czas niedostępności. Łatka została przygotowana pod trzy wersje: Redis 3.2, Redis 5.0 i najbardziej aktualny branch Redis Unstable. Wprowadza ona parametr
sentinel ignore-max-down-timedo głównego pliku konfiguracyjnego Sentinela za pomocą którego możemy sterować logiką odpowiedzialną za weryfikację replik i punktu związanego z przesunięciem replikacji. Oczywiście nie zaburza ona w żaden sposób elementów takich jak kworum czy większość — one nadal mają najwyższy priorytet i muszą zostać spełnione aby nowy mechanizm zadziałał. Sprawdza się on jedynie, jeśli pierwszą z instancji, która będzie online po awarii, będzie jedna z replik (oczywiście przy spełnionym kworum i wymaganej większości). Została przeze mnie przetestowana jednak nie zalecam jej stosowania na środowiskach produkcyjnych.
R1 staje się online #
Po ręcznym wypromowaniu nowego mistrza można z powrotem zalogować się do aplikacji. Mamy jednak jedną instancję Redis, tj. R2 i żadnej instancji zapasowej. Jeżeli w tej sytuacji uruchomiony zostanie R3 (Slave), wszystko będzie działać poprawnie, ponieważ Sentinel na każdym z węzłów jest natychmiast aktualizowany i wie, co dzieje się z sąsiadami — S3 będzie wiedział, kto jest teraz nowym mistrzem i gdzie znajdują się aktualne repliki.
Zatrzymajmy się na dosłownie 2 minuty. Jeżeli w takiej sytuacji w jakiś magiczny sposób mistrz straci wszystkie dane, to w przypadku repliki, która stanie się dostępna, przechowywane przez nią klucze także zostaną utracone z powodu synchronizacji z mistrzem. W niektórych przypadkach, jeśli używasz replikacji, warto upewnić się, że repliki nie są automatycznie uruchamiane zaraz po awarii. W wielu sytuacjach chcemy jak najszybciej uzyskać dostępność działania Redisa, jednak zdarzają się takie sytuacje, w których utrata danych może być bardzo bolesna. Jeśli repliki będą próbowały być dokładną kopią instancji nadrzędnej, w przypadku uruchomienia go ponownie z pustym zestawem danych, repliki zostaną również wyczyszczone.
Wróćmy do przykładu. Jeśli jednak zamiast R3 uruchomiony zostanie R1 (stary Master) sytuacja przez chwilę będzie niezwykle ciekawa, ponieważ można pomyśleć, że dojdzie do pewnej rywalizacji o przodownictwo w grupie, z racji tego, że przez chwilę będą dwa serwer nadrzędne. Nic z tych rzeczy. Pamiętaj, że S1 ma także zaktualizowaną konfigurację, dzięki czemu R1 automatycznie zostanie zdegradowany do roli serwera podrzędnego. Poniżej znajduje się potwierdzenie przeprowadzonej konwersji:
+convert-to-slave slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
Co więcej, przypomnij sobie, co powiedziałem w jednym z powyższych rozdziałów: Sentinel stara się ograniczyć przełączanie instancji nadrzędnej tak mocno jak to tylko możliwe, aby zminimalizować możliwość uszkodzenia danych.
R2 znów staje się niedostępny #
W poprzednim punkcie udało się uruchomić jedną z replik, tj. R1, która zaraz po restarcie została skonwertowana do roli podrzędnej. W sytuacji kiedy na R2 (obecny Master) Redis znów przestanie być dostępny, Redis Sentinel automatycznie wypromuje R1 (R3 nadal nie działa) na instancję główną po upłynięciu czasu zdefiniowanego za pomocą down-after-milliseconds, aktualizując wszystkie swoje konfiguracje tak, aby każdy z węzłów znał aktualny stan swój jak i pozostałych członków grupy. Pamiętaj jednak, że taki scenariusz nie zawsze się powiedzie, zwłaszcza jeśli Sentinele nie będą w stanie znaleźć odpowiedniej repliki do awansu.
W tej sytuacji w dzienniku pojawią się poniższe wpisy:
+sdown master mymaster 192.168.10.20 6379
+odown master mymaster 192.168.10.20 6379 #quorum 2/2
+new-epoch 9083
+try-failover master mymaster 192.168.10.20 6379
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 9083
ef58a52e53566fde8106b9112ea4b9689023e35e voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 9083
f647de705536775591595dfb543a739924ce4364 voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 9083
+elected-leader master mymaster 192.168.10.20 6379
+failover-state-select-slave master mymaster 192.168.10.20 6379
+selected-slave slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+failover-state-send-slaveof-noone slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+failover-state-wait-promotion slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+promoted-slave slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+failover-state-reconf-slaves master mymaster 192.168.10.20 6379
+failover-end master mymaster 192.168.10.20 6379
+switch-master mymaster 192.168.10.20 6379 192.168.10.10 6379
+slave slave 192.168.10.30:6379 192.168.10.30 6379 @ mymaster 192.168.10.10 6379
+slave slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
+sdown slave 192.168.10.20:6379 192.168.10.20 6379 @ mymaster 192.168.10.10 6379
+sdown slave 192.168.10.30:6379 192.168.10.30 6379 @ mymaster 192.168.10.10 6379
Widzimy, że znaleźliśmy replikę, którą udało się wybrać na nowy serwer nadrzędny do awansu (przy okazji przypomnij sobie przeciwny stan, którym jest failover-abort-no-good-slave):
+selected-slave slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+failover-state-send-slaveof-noone slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
Następnie należy odczekać pewien czas, aż serwer podrzędny zmieni rolę na nową:
+failover-state-wait-promotion slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
Kolejne wpisy informują, że doszło do awansowania nowego mistrza, oraz że nowy stan węzłów Sentinel został zapisany do pliku konfiguracyjnego dzięki wywołaniu funkcji sentinelFlushConfig. W czasie wykonania tych operacji przeprowadzone zostają dodatkowe czynności takie jak zwolnienie i aktualizacja adresów oraz portów działających instancji:
+promoted-slave slave 192.168.10.10:6379 192.168.10.10 6379 @ mymaster 192.168.10.20 6379
+failover-state-reconf-slaves master mymaster 192.168.10.20 6379
Poniżej widzimy, że proces przełączania zakończył się sukcesem, a także, że wszystkie repliki zostały ponownie skonfigurowane w celu replikacji z nowym mistrzem:
+failover-end master mymaster 192.168.10.20 6379
+switch-master mymaster 192.168.10.20 6379 192.168.10.10 6379
Alternatywą dla failover-end jest failover-end-for-timeout, który mówi, że przełączanie awaryjne zostało zakończone z powodu przekroczenia limitu czasu, a repliki zostaną ostatecznie skonfigurowane do komunikacji z nowym serwerem głównym. Drugi wpis określa natomiast, że wykonano aktualizację mistrza. Jest to bardzo cenna informacja dla klientów, którzy mogą od teraz łączyć się z nową instancją główną.
R2 ponownie staje się dostępny #
R1 jest aktualnym mistrzem natomiast po chwili R2 został po raz kolejny przywrócony do działania. Powinniśmy móc przewidzieć, co się stanie, mianowicie R2 (stary Master) zostanie zdegradowany do roli Slave, a mistrzem wciąż będzie R1.
R1 niedostępny, R2 i R3 online #
Niestety nasze środowisko nie działa stabilnie. Problemy powodują, że R1 (obecny Master) nie działa natomiast w tej samej chwili R2 i R3 stają się dostępne. Co wtedy?
Oto konfiguracja obu węzłów zaraz po uruchomieniu (pokazane zostały najważniejsze parametry):
### R2 ###
192.168.10.20
replicaof 192.168.10.10 6379
replica-priority 10
replica-read-only no
protected-mode yes
sentinel myid f647de705536775591595dfb543a739924ce4364
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-sentinel mymaster 192.168.10.30 26379 c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
### R3 ###
192.168.10.30
replicaof 192.168.10.10 6379
replica-priority 100
replica-read-only no
protected-mode yes
sentinel myid c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.10 6379 2
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-replica mymaster 192.168.10.30 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
Mamy dwa serwery podrzędne i żadnego węzła głównego, logowanie do aplikacji nie działa, pojawia się Project Manager i 10 innych osób, które napierają i wywierają presję. Co robić?
Spróbujmy wykorzystać Redis Sentinela do próby automatycznego awansowania jednej z replik na instancję główną:
127.0.0.1:26379> SENTINEL failover mymaster
(error) NOGOODSLAVE No suitable replica to promote
Upss! Niestety Redis Sentinel w tej sytuacji nam nie pomoże. Zna on jednak adres obecnego mistrza, który nie działa i zna lokalizację obu replik, które działają. Do przepięcia wymagane jest kworum ustawione na 2, więc skoro mamy trzy działające Sentinele i dwa działające węzły Redis, to w czym problem?
W takiej sytuacji także należy wykonać ręczne awansowanie jednej z replik za pomocą polecenia SLAVEOF no one (przyjmijmy, że R2), dzięki czemu uzyskamy ponownie instancję nadrzędną. Pamiętajmy jednak, że ta komenda nie pomaga Sentinelowi uporządkować konfiguracji. Opisana przed chwilą sytuacja jest praktycznie tożsama z tą, w której serwer R2 stał się dostępny i został uruchomiony ze swoją starą rolą serwera podrzędnego. Natomiast ręczne przełączanie za pomocą komendy SENTINEL failover można wykonać jedynie, kiedy repliki nadal działają i nie uległy wcześniej awarii (można to zrobić nawet przy działającym jednym wartowniku!), w przeciwnym razie należy użyć polecenia SLAVEOF no one, które jest jedynym i nieidealnym rozwiązaniem.
Wszystkie węzły ponownie dostępne #
Stało się! Udało nam się doprowadzić wszystkie instancje to działania. Przypomnijmy sobie jednak status przed pełnym przywróceniem:
- R2 (Master)
- R3 (Slave)
Skoro tak, to R1 także działa i zaraz po uruchomieniu będzie miał status mistrza tak samo jak R2. Nie będzie to jednak problemem dla Sentinela, ponieważ jego konfiguracja jest zsynchronizowana w całej grupie instancji i R1 zostanie automatycznie zdegradowany do repliki.
Scenariusz testowy: etap 2 #
W tym etapie zaprezentuję jedynie dwie sytuacje:
- kiedy pozostają dwa działające Sentinele z kworum równym dwa
- kiedy pozostaje jeden działający Sentinel z kworum równym jeden
Dwa działające Sentinele i kworum 2 #
Przyjmijmy, że jeden z Sentineli (S1) uległ awarii i mamy dwa, które są dostępne, tj. S2 i S3. Mamy też konfigurację początkową złożoną z węzłów 1x Master (R1) oraz 2x Slave (R2 i R3).
R1 ulega awarii. Przełączanie awaryjne zakończy się sukcesem, ponieważ w grupie Sentineli są dwa działające, mają zaktualizowane konfiguracje oraz zachowane zostaje kworum. S3 natomiast został mianowany na lidera całego procesu:
### S2 ###
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 12094
### S3 ###
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 12094
f647de705536775591595dfb543a739924ce4364 voted for c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 12094
+elected-leader master mymaster 192.168.10.10 6379
W międzyczasie S2 zaktualizował informacje o konfiguracji z S3:
+config-update-from sentinel c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 192.168.10.30 26379 @ mymaster 192.168.10.10 6379
Nowym mistrzem zostanie R2, ponieważ ma wyższy priorytet (równy 10) oraz spełnia wszystkie niezbędne wymagania, aby zostać instancją główną. Oczywiście ręczne przełączanie za pomocą SENTINEL failover również działa.
Jeden działający Sentinel i kworum 1 #
Przyjmijmy, że jeden z Sentineli (S1) uległ awarii i mamy dwa, które są dostępne, tj. S2 i S3. Mamy też konfigurację początkową złożoną z węzłów 1x Master (R1) oraz 2x Slave (R2 i R3). Następnie R1 ulega awarii. Przełączanie awaryjne zakończy się sukcesem, ponieważ w grupie Sentineli są dwa działające, mają zaktualizowane konfiguracje oraz zachowane zostaje kworum. Jeden z działających Sentineli został mianowany na lidera całego procesu.
Po chwili S2 staje się niedostępny co powoduje, że S3 stał się jedynym wartownikiem w grupie. W logach Redis Sentinela na S3 odłoży się następujący komunikat (odkłada się on zawsze w przypadku awarii wartownika na każdym działającym węźle, który pozostał):
+sdown sentinel f647de705536775591595dfb543a739924ce4364 192.168.10.20 26379 @ mymaster 192.168.10.20 6379
Co się stanie, jak S2 ulegnie awarii i zostanie tylko jeden wartownik i po chwili awarii ulegnie serwer główny R2? Nie uda się wykonać procedury przełączania awaryjnego, ponieważ nie ma dodatkowego wartownika, który potwierdziłby ten proces i zaakceptował lidera. W obecnej sytuacji, w dzienniku zalogowane zostaną poniższe komunikaty:
+new-epoch 12118
+try-failover master mymaster 192.168.10.20 6379
+vote-for-leader c8e2591af9d8437bdafd78ccdc6c5b9f618613d6 12118
-failover-abort-not-elected master mymaster 192.168.10.20 6379
Next failover delay: I will not start a failover before Tue Sep 22 12:49:35 2020
Tak samo, gdyby z jakiegoś względu najpierw dwa z trzech Sentineli uległy awarii, a następnie mistrz stał się niedostępny, to przy kworum równym jeden i jednym działających wartowniku, nie doszłoby do awansu jednej z dwóch działających replik. Wróćmy jednak do stanu, gdzie R2 (Master), R3 (Slave) oraz S3 (Sentinel) działają. Czy w tej sytuacji uda się wykonać ręczne przełączanie za pomocą SENTINEL failover?
127.0.0.1:26379> SENTINEL failover mymaster
OK
Ta, dam! Dokonaliśmy przełączenia awaryjnego. Po pierwsze dlatego, że w grupie węzłów była nadal instancja nadrzędna, po drugie dlatego, że wykonaliśmy ten proces ręcznie. Przypomnij sobie sytuację z jednego z powyższych rozdziałów, kiedy mieliśmy dwa serwery podrzędne i żadnego węzła głównego. Wykonaliśmy wtedy ręczny failover, który zakończył się niepowodzeniem:
127.0.0.1:26379> SENTINEL failover mymaster
(error) NOGOODSLAVE No suitable replica to promote
Nie jest to jednak taka sama sytuacja, ponieważ mieliśmy wtedy dwie działające repliki, które „wróciły” z awarii, więc przerwa w replikacji mogła być jednym z powodów takiego stanu (pamiętajmy także o kworum równym jeden).
Jeżeli znajdziemy się w sytuacji, gdzie padły S1 i S2 oraz R1 i R2, zgodnie z powyższym rozumowaniem będziemy mieli jedną instancję Slave oraz jednego wartownika. Co się stanie, jak spróbujemy teraz wykonać ręczne przełączanie? Oto wynik działania na R3:
redis.stats
192.168.10.30
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 100
replica-read-only no
protected-mode yes
sentinel myid c8e2591af9d8437bdafd78ccdc6c5b9f618613d6
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
sentinel monitor mymaster 192.168.10.30 6379 1
sentinel auth-pass mymaster meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 5000
sentinel known-replica mymaster 192.168.10.10 6379
sentinel known-replica mymaster 192.168.10.20 6379
sentinel known-sentinel mymaster 192.168.10.10 26379 ef58a52e53566fde8106b9112ea4b9689023e35e
sentinel known-sentinel mymaster 192.168.10.20 26379 f647de705536775591595dfb543a739924ce4364
---------------------------------------
# Replication
role:master
connected_slaves:0
master_replid:24ef75bca3aa6607dedbd945f1c2704e8240bddb
master_replid2:80ff94e7f74c5082fe736a5a40f089287da3b60b
master_repl_offset:48360
second_repl_offset:45906
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:41391
repl_backlog_histlen:6970
PONG
Przełączanie ponownie zakończyło się sukcesem, najprawdopodobniej z tych samych względów jak wyżej, dzięki czemu instancja podrzędna przeszła w rolę Master.
Podsumowanie #
Jeżeli dotrwałeś do końca to świetnie. W tej części poznaliśmy czym jest Redis Sentinel natomiast w ostatniej omówimy dodatkowe usługi takie jak HAProxy oraz Twemproxy, które pozwolą znacznie usprawnić działanie instancji Redis oraz Sentinel. Już na sam koniec podsumujmy szybko, co zostało powiedziane, odpowiadając na pytania z początku tego wpisu.
Dlaczego minimalna zalecana ilość Sentineli wynosi trzy?
Głównym powodem jest to, że mamy wtedy odpowiedni zapas Sentineli do poprawnego działania mechanizmu przełączania w przypadku awarii jednego z nich (jeśli zostaną dwa). Co równie istotne, zachowanie nieparzystej liczby Sentineli jest lepsze dla algorytmu konsensusu, który pomaga w porozumieniu i ostatecznym wyborze lidera, który przeprowadzi cały proces.
Dlaczego kworum nie zawsze jest większością jednak w jakich przypadkach może mieć na nią wpływ?
Kworum jest minimalną liczbą Sentineli, które muszą potwierdzić stan ODOWN serwera nadrzędnego. Jeżeli ustawimy wartość mniejszą niż większość, to jest to minimalna liczba, jaka musi zaakceptować niedostępność mistrza. Jeżeli jest większa bądź równa większości (50% + 1) to jest to minimalna liczba, jaka musi być zaakceptowana do potwierdzenia niedostępności instancji głównej.
Dlaczego przy dwóch działających Sentinelach przełączanie awaryjne nadal działa?
Ponieważ nadal jest zachowana większość, tj. kworum, które jest wymagane do akceptacji niedostępności instancji nadrzędnej. Ponadto zachowana jest też większość, która wymagana jest do akceptacji wyboru lidera (który dokona przełączania) oraz autoryzacji tego procesu.
Dlaczego przy jednym działającym Sentinelu i kworum równym jeden przełączanie awaryjne nie działa?
Ponieważ nie jest zachowana minimalna ilość Sentineli do autoryzacji tego procesu. Jeśli liczba głosów w wyborach uzyskanych przez dany węzeł Sentinel osiągnie wymagane minimum (czyli według wzoru S / 2 + 1), węzeł Sentinel zostanie wybrany jako lider, w przeciwnym razie wybory zostaną powtórzone, co z dużym prawdopodobieństwem doprowadzi do ostatecznego niepowodzenia całego mechanizmu.
Dlaczego Sentinele (przy zachowaniu większości) awansują ostatni działający węzeł, który jest w stanie Slave?
Ponieważ nie wykryto jego niedostępności i nadal działa, co oznacza, że nie był w jednym z trzech stanów, tj. SDOWN, ODOWN lub DISCONNECTED oraz odpowiada na komendę PING i INFO. Oczywiście, aby zakwalifikować go jako odpowiedni do przełączenia, muszą zostać spełnione jeszcze inne warunki.
Dlaczego Sentinele (przy zachowaniu większości) nie awansuję węzła, który jest w stanie Slave i został uruchomiony jako pierwszy po awarii?
Jest to przeciwieństwo odpowiedzi poprzedniej i ma związek z całym algorytmem i odpowiednimi warunkami do spełnienia (odrzucenie węzłów podrzędnych nienadających się do promowania), by przeprowadzić proces awansowania. Podobna sytuacja będzie miała miejsce, jeśli wszystkie węzły staną się niedostępne, a następnie wstaną wszystkie serwery podrzędne z wyjątkiem mistrza — każdy z tych węzłów pozostanie w stanie Slave do momentu, aż jeden z nich nie zostanie awansowany ręcznie przez administratora.
Rozwiązaniami problemu zapisów dla repliki, która nie zostanie automatycznie awansowana na instancję główną są:
- ręczne wypromowanie przez administratora (także z poziomu Sentinela)
- wykorzystanie rozwiązania Active-Replica lub Multi-Master forka projektu o nazwie KeyDB
- wyłączenie trybu tylko do odczytu dla replik (może powodować wiele problemów)