KeyDB: Replikacja Active-Replica i Multi-Master
16 Oct 2020
database keydb nosql performance redis replication
W poprzedniej serii wpisów przedstawiłem w miarę dokładnie, na czym polega replikacja Master-Slave w Redisie oraz w jaki sposób zapewnić wysoką dostępność za pomocą rozwiązania składającego się z trzech instancji.
Jeżeli chwilę się zastanowisz, to najprawdopodobniej stwierdzisz, że mogą pojawić się przypadki, w których przydałoby się wykorzystać replikację złożoną z więcej niż jednego mistrza. Niestety Redis nie wspiera takiej implementacji i żeby ją zestawić za jego pomocą, musielibyśmy wykorzystać rozwiązanie podobne do Active-Active Geo-Distribution (CRDTs-Based). Więcej na ten temat poczytasz w artykule High Availability and Scalability with Redis Enterprise.
Z drugiej strony, czy istnieje rozwiązanie Open Source, które zapewniłoby taki sposób działania Redisa? Jest kilka możliwości rozwiązania tego problemu. W tym wpisie przedstawię alternatywne rozwiązanie oparte na forku projektu Redis zwanym KeyDB.
Czym jest KeyDB? #
Autorzy projektu opisują go jako w pełni zgodny z Redisem i wysokowydajny fork ukierunkowany na wielowątkowość, wydajność pamięci i wysoką przepustowość. Myślę, że można go traktować bardziej jako solidny dodatek z kilkoma ekstra funkcjami. Co istotne, dostarcza on niektóre z mechanizmów projektu Redis Enterprise w tym ten, który nas interesuje najbardziej, czyli aktywną replikację.
Jedną z największych zalet, o której wspominają autorzy, jest wydajność w porównaniu z oryginałem. Na stronie głównej projektu przedstawiono to w ten sposób:
On the same hardware KeyDB can perform twice as many queries per second as Redis, with 60% lower latency. Active-Replication simplifies hot-spare failover allowing you to easily distribute writes over replicas and use simple TCP based load balancing/failover. KeyDB's higher performance allows you to do more on less hardware which reduces operation costs and complexity.
Więcej informacji na temat testów i porównań znajdziesz we wpisie A Multithreaded Fork of Redis That’s 5X Faster Than Redis.
Proces instalacji i czynności wstępne #
W pierwszej kolejności przejdźmy do instalacji (wykorzystałem system CentOS 7), która jest niezwykle prosta i szybka. Oczywiście istnieje możliwość zbudowania pakietu ze źródeł, co zostało dokładnie opisane we wpisie Building KeyDB.
Najpierw pobierzmy klucz GPG repozytorium i dodajmy go do bazy kluczy:
rpm --import https://download.keydb.dev/packages/rpm/RPM-GPG-KEY-keydb
Następnie pobierzmy paczkę i zainstalujmy ją:
https://download.keydb.dev/packages/rpm/centos7/x86_64/keydb_all_versions/keydb-6.0.16-1.el7.x86_64.rpm
yum install ./keydb-6.0.16-1.el7.x86_64.rpm
Na koniec dodajmy uruchamianie usługi przy starcie systemu:
systemctl enable keydb
Przed przystąpieniem do edycji plików konfiguracyjnych wykonajmy kilka zadań w celu wprowadzenia pewnego porządku. W pierwszej kolejności utworzymy kopię głównego pliku konfiguracyjnego:
cp /etc/keydb/keydb.conf /etc/keydb/keydb.conf.orig
Następnym krokiem jest posprzątanie w konfiguracji, czyli na podstawie oryginalnego pliku wyfiltrujemy tylko faktyczne dyrektywy z pominięciem komentarzy:
egrep -v '#|^$' /etc/keydb/keydb.conf.orig > /etc/keydb/keydb.conf
Jeżeli zależy Ci na dokładniejszym dostosowaniu konfiguracji, zerknij do oficjalnej dokumentacji projektu lub do poprzednich moich wpisów dotyczących Redisa, w których dosyć dokładnie wyjaśniłem najważniejsze z parametrów.
Replikacja Active-Replica #
Domyślnie KeyDB działa tak, jak Redis i zezwala tylko na jednokierunkową komunikację z instancji głównej do repliki. Natomiast typ replikacji Active-Replica znacznie upraszcza scenariusze przełączania awaryjnego, ponieważ repliki nie muszą już być promowane do instancji nadrzędnych. Ponadto ten tryb replikacji pozwala na lepsze rozłożenie obciążenia w scenariuszach opartych na zapisach. Poprawia także odczyty i zapisy w obu wykorzystywanych instancjach, co może zwiększyć ich liczbę przy dużym obciążeniu, a także przygotować repliki do pracy w przypadku awarii, co jest niemożliwe w przypadku replikacji Master-Slave złożonej z dwóch węzłów.
Ten tryb replikacji nadaje się idealnie w scenariuszach, w których masz dwa węzły i chcesz zapewnić odpowiednią wydajność zapisów lub zależy Ci na zachowaniu pełnej odporności na awarie. Więcej na ten temat poczytasz w rozdziale Active Replica Setup oficjalnej dokumentacji.
Istnieje jeszcze jedna, niezwykle ważna zaleta takiego rozwiązania. Otóż pozwala ono na wyeliminowanie sytuacji, w których połączenie między węzłami nadrzędnymi jest zrywane, ale zapisy są nadal wykonywane, przez co może dojść do sytuacji, w której dwie instancje mają ten sam klucz o różnej wartości. W KeyDB rozwiązana to tak, że każdy zapis jest oznaczony znacznikiem czasu, a po przywróceniu połączenia każdy mistrz udostępni swoje nowe dane. Zapisy z najnowszym znacznikiem czasu mają pierwszeństwo, co zapobiega zastępowaniu nowych danych zapisanych po zerwaniu połączenia przez stare dane.
Poniżej znajduje się poglądowy zrzut prezentujący to, w jaki sposób zostanie zestawiony ten typ replikacji:
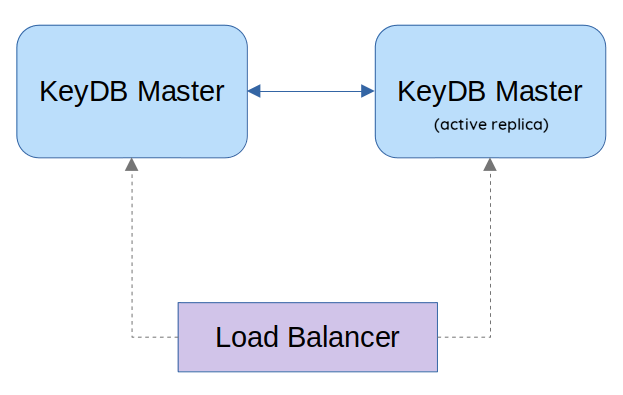
Wszelkie komendy uruchomione w jednym węźle będą widoczne w drugim węźle. Jeśli jeden z serwerów ulegnie awarii, sygnatura czasowa zapewni, że replika nie nadpisze nowszych zapisów, gdy zostanie przywrócona do trybu online. Przy bardzo dużym obciążeniu może wystąpić niewielkie opóźnienie.
Z technicznych rzeczy, jakie się pojawiają w porównaniu ze zwykłym trybem pracy Master-Slave, są dynamicznie generowane identyfikatory. Nie są one nigdzie zapisywane i istnieją tylko przez cały czas działania procesu. Są one używane głównie w celu zapobiegania ponownemu rozpowszechnianiu zmian do serwera głównego.
Konfiguracja tego typu replikacji sprowadza się tak naprawdę do ustawienia parametrów active-replica yes i replica-read-only no na każdym z węzłów, przy czym drugi z parametrów po włączeniu pierwszej automatycznie przyjmuje wartość no, chyba że został jawnie wskazany w konfiguracji.
Cała konfiguracja z rozbiciem na węzły wygląda jak poniżej:
### R1 ###
bind 192.168.10.10 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
active-replica yes
replica-read-only no
replicaof 192.168.10.20 6379
### R2 ###
bind 192.168.10.20 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
active-replica yes
replica-read-only no
replicaof 192.168.10.10 6379
Uruchamiając obie instancje, po wydaniu polecenia INFO replication zobaczymy cztery istotne parametry:
192.168.10.10:6379> INFO replication
# Replication
role:active-replica
master_global_link_status:up
master_host:192.168.10.20
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_repl_offset:319620
slave_priority:100
slave_read_only:0
connected_slaves:1
slave0:ip=192.168.10.20,port=6379,state=online,offset=321520,lag=0
master_replid:f5093d23b283d0e32a357d9b0ce1c15c77593227
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:321520
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:319195
repl_backlog_histlen:2326
192.168.10.20:6379> INFO replication
# Replication
role:active-replica
master_global_link_status:up
master_host:192.168.10.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:320015
slave_priority:100
slave_read_only:0
connected_slaves:1
slave0:ip=192.168.10.10,port=6379,state=online,offset=321171,lag=1
master_replid:0ac9e564a25e1d4f63946aa5bb5a15205623ae0d
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:321171
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:318823
repl_backlog_histlen:2349
Pierwszy z nich to rola danego węzła, która przy poprawnej konfiguracji przyjmie wartość active-replica. Dwa pozostałe parametry powinny być nam znane i są nimi master_host określający instancję nadrzędną danego węzła oraz slave0, którego wartością jest podpięty węzeł nadrzędny. Widzimy, że w takiej konfiguracji każda z instancji w obu parametrach będzie miała lokalizację drugiego węzła. Czwarty parametr, tj. master_global_link_status określa ogólny status instancji nadrzędnej w całej grupie. W przypadku awarii jednego z węzłów jej status będzie miał wartość down.
Możemy teraz utworzyć testowo klucz na jednym z węzłów:
192.168.10.10:6379> SET foo bar
OK
I zweryfikować czy jest widoczny na każdym z nich:
### R1 ###
192.168.10.10:6379> GET foo
"bar"
### R2 ###
192.168.10.20:6379> GET foo
"bar"
Replikacja Multi-Master #
Kolejnym rodzajem replikacji jest replikacja Multi-Master, która pozwala na obsługę wielu instancji nadrzędnych. Jest ona jednak nadal w fazie eksperymentalnej. Jeśli Twoje środowiska nie ma wygórowanych wymagań i zamierzasz wykorzystać tylko dwa węzły KeyDB, użyj replikacji Active-Replica, ponieważ jest bardziej stabilna niż Multi-Master i przetestowana pod kątem obsługi dużych obciążeń.
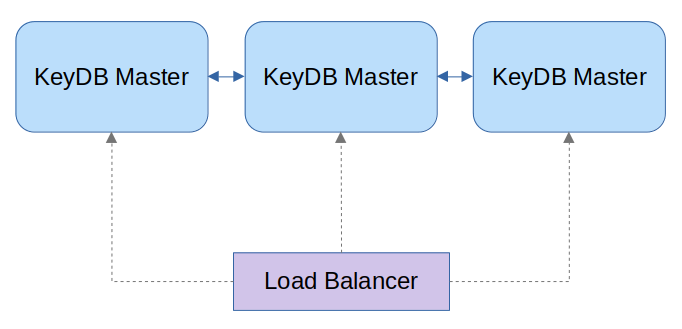
Oficjalna dokumentacja wspomina o niezwykle ważnej kwestii jeśli chodzi o zasadę działania w porównania z tradycyjnym modelem replikacji:
- wielokrotne wywołania polecenia
replicaofspowodują dodanie kolejnych węzłów, a nie zastąpienie aktualnego - KeyDB nie usuwa swojej bazy danych podczas synchronizacji z serwerem głównym
- KeyDB połączy wszystkie polecenia odczytu i zapisu, które odebrał z mistrza z własną wewnętrzną bazą danych
- KeyDB domyślnie nadaje najwyższy priorytet ostatnio wykonanej operacji
Oznacza to, że replika z wieloma mistrzami będzie zawierała nadzbiór danych wszystkich instancji głównych. Jeśli dwie instancje nadrzędne mają różną wartość tego samego klucza, nie jest zdefiniowane, który klucz zostanie przyjęty. Jeśli instancja główna usunie klucz, który istnieje w innym węźle głównym, replika nie będzie już zawierała kopii tego klucza.
Ten tryb replikacji nadaje się idealnie w scenariuszach, w których masz więcej niż dwa węzły i chcesz zapewnić odpowiednią wydajność zapisów lub zależy Ci na zachowaniu pełnej odporności na awarie. Więcej na ten temat poczytasz w rozdziale Using Multiple Masters oficjalnej dokumentacji.
Oficjalna dokumentacja opisuje możliwe zalety wykorzystania tego trybu:
With multi-master setup you make each master a replica of other nodes. This can accept many topologies, you could make different variations of ring topologies or make every master a replica of all other masters. If not all are synced, consider failure scenarios and ensure that one break wont cause others to lose their connections.
Konfiguracja tego trybu jest niezwykle podobna do tego omawianego we wcześniejszym rozdziale i sprowadza się do ustawienia parametru multi-master yes oraz odpowiedniego wskazania pozostałych węzłów Master.
Cała konfiguracja z rozbiciem na węzły wygląda jak poniżej:
### R1 ###
bind 192.168.10.10 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
multi-master yes
active-replica yes
replica-read-only no
replicaof 192.168.10.20 6379
replicaof 192.168.10.30 6379
### R2 ###
bind 192.168.10.20 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
multi-master yes
active-replica yes
replica-read-only no
replicaof 192.168.10.10 6379
replicaof 192.168.10.30 6379
### R3 ###
bind 192.168.10.30 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
multi-master yes
active-replica yes
replica-read-only no
replicaof 192.168.10.10 6379
replicaof 192.168.10.20 6379
Uruchamiając każdą z instancji, po wydaniu polecenia INFO replication zobaczymy ponownie cztery istotne parametry oraz kilka dodatkowych informacji:
192.168.10.10:6379> INFO replication
# Replication
role:active-replica
master_global_link_status:up
master_host:192.168.10.30
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:4323
master_1_host:192.168.10.20
master_1_port:6379
master_1_link_status:up
master_1_last_io_seconds_ago:8
master_1_sync_in_progress:0
slave_repl_offset:4369
slave_priority:100
slave_read_only:0
connected_slaves:2
slave0:ip=192.168.10.20,port=6379,state=online,offset=7047,lag=1
slave1:ip=192.168.10.30,port=6379,state=online,offset=7047,lag=0
master_replid:10b8b05f4121996cf8ba64880140e8e1a8abce63
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7047
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:4826
repl_backlog_histlen:2222
192.168.10.20:6379> INFO replication
# Replication
role:active-replica
master_global_link_status:up
master_host:192.168.10.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:6187
master_1_host:192.168.10.30
master_1_port:6379
master_1_link_status:up
master_1_last_io_seconds_ago:8
master_1_sync_in_progress:0
slave_repl_offset:4323
slave_priority:100
slave_read_only:0
connected_slaves:2
slave0:ip=192.168.10.30,port=6379,state=online,offset=5229,lag=0
slave1:ip=192.168.10.10,port=6379,state=online,offset=5229,lag=0
master_replid:15640f5845c0c8f99e17a38976139486ffc4b9bf
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:5229
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:3008
repl_backlog_histlen:2222
192.168.10.30:6379> INFO replication
# Replication
role:active-replica
master_global_link_status:up
master_host:192.168.10.20
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:4323
master_1_host:192.168.10.10
master_1_port:6379
master_1_link_status:up
master_1_last_io_seconds_ago:8
master_1_sync_in_progress:0
slave_repl_offset:6141
slave_priority:100
slave_read_only:0
connected_slaves:2
slave0:ip=192.168.10.10,port=6379,state=online,offset=5183,lag=0
slave1:ip=192.168.10.20,port=6379,state=online,offset=5183,lag=1
master_replid:c77d822c70f3b13b48eeb39ac898d545dadbb6fc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:5183
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2985
repl_backlog_histlen:2199
Widzimy, że każdy z węzłów posiada dodatkowo lokalizację i parametry drugiej instancji głównej:
### R3 ###
master_host:192.168.10.20
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:4323
master_1_host:192.168.10.10
master_1_port:6379
master_1_link_status:up
master_1_last_io_seconds_ago:8
master_1_sync_in_progress:0
slave_repl_offset:6141
Oraz parametry slave0 i slave1, które zawierają lokalizację i parametry pozostałych instancji nadrzędnych. Możemy teraz utworzyć testowo klucz na jednym z węzłów:
192.168.10.10:6379> SET bar foo
OK
I zweryfikować czy jest widoczny na każdym z nich:
### R1 ###
192.168.10.10:6379> GET bar
"foo"
### R2 ###
192.168.10.20:6379> GET bar
"foo"
### R3 ###
192.168.10.30:6379> GET bar
"foo"
Konfiguracja HAProxy #
Pozostaje jeszcze wybór odpowiedniego load balancera, którym w tym przykładzie będzie HAProxy z bardzo prostą konfiguracją:
global
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
user haproxy
group haproxy
maxconn 512
nbproc 2
nbthread 2
defaults redis
mode tcp
timeout connect 4s
timeout server 10s
timeout client 10s
log global
option tcplog
frontend http
bind *:8080
default_backend stats
backend stats
mode http
stats enable
stats uri /
stats refresh 5s
stats show-legends
stats auth ha-admin:piph1NeiceHe
frontend ft_redis
bind :16379 name redis
default_backend bk_redis
backend bk_redis
log global
balance roundrobin
server R1 192.168.10.10:6379 check inter 1s
server R2 192.168.10.20:6379 check inter 1s
server R3 192.168.10.30:6379 check inter 1s
Możemy ją zastosować dla obu typów replikacji. Zwróć uwagę na rodzaj równoważenia obciążenia, czyli techniki używanej do dystrybucji obciążenia. W zastosowanym tutaj trybie tj. roundrobin, load balancer ma listę serwerów i przekazuje każde żądanie do każdego serwera z listy w odpowiedniej kolejności. Po osiągnięciu ostatniego serwera pętla ponownie przeskakuje do pierwszego serwera i zaczyna się od nowa.
Należy mieć świadomość pewnych problemów, jakie mogą się pojawić, zwłaszcza gdy bierze się pod uwagę długość lub zapotrzebowanie na przetwarzanie połączenia. Gdy ruch jest znaczny lub połączenia są długie i zaczynają się gromadzić, obciążenie na serwerach, które otrzymują takie połączenia, może znacznie wzrastać.
Przetestujmy na koniec czy zapisy i odczyty w powyższej konfiguracji propagują się w odpowiedni sposób i czy istnieje możliwość połączenia się do instancji KeyDB przez HAProxy:
redis-cli -h 192.168.10.20 -p 16379 -a <password> SET xyz 123
OK
for i in 192.168.10.10 192.168.10.20 192.168.10.30 ; do
redis-cli -h "$i" -p 16379 -a <password> GET xyz
done
"123"
"123"
"123"
Oczywiście nic nie stoi na przeszkodzie, abyś dostosował odpowiednią metodę równoważenia obciążenia w zależności od środowiska i instancji, które wykorzystujesz.