Redis: 3 instancje i replikacja Master-Slave cz. 1
12 Sep 2020
database debugging nosql performance redis redis-cluster redis-sentinel replication
W tym wpisie zajmiemy się podstawowym trybem pracy Redisa jakim jest asynchroniczna replikacja Master-Slave.
Replikacja Master-Slave #
Konfigurację Redisa zaprezentowaną w tej serii wpisów przedstawia poniższy zrzut i na tę chwilę traktujmy go jako coś, co pokazuje podstawowe, jednak niezwykle istotne informacje:
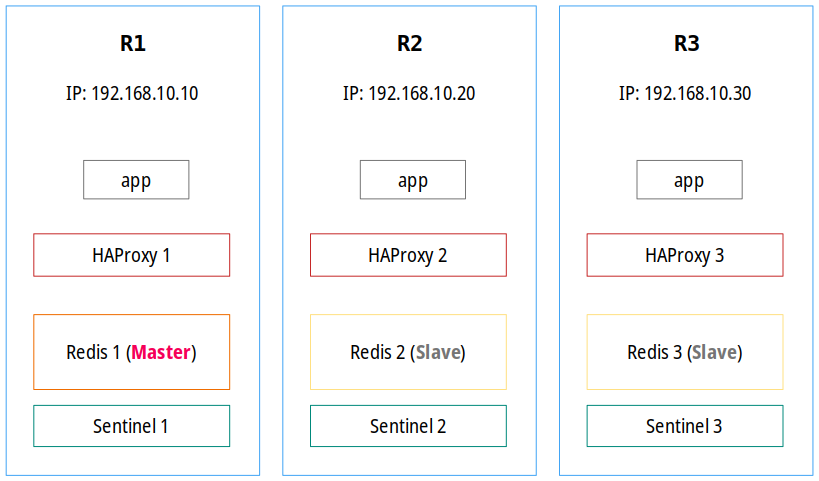
Wykorzystanie HAProxy w tym zestawie wprowadza pewną inteligencję, dzięki której serwer nadrzędny jest automatycznie wykrywany na każdym węźle, więc jeśli działa, aplikacja zawsze pisze do niego. Jeśli węzeł główny stanie się niedostępny, jeden z węzłów podrzędnych przejmuje rolę nadrzędną (zarządza tym Redis Sentinel). HAProxy wykrywa, że Master się zmienił, a następnie zmienia węzeł odbierający cały ruch (odpowiedzialny za zapisy). W związku z tym HAProxy musi sprawdzać/monitorować przełączanie awaryjne i aktualizować/ponownie łączyć się z serwerem nadrzędnym w razie potrzeby. Oczywiście nic nie stoi na przeszkodzie, aby wprowadzić optymalizację i skonfigurować aplikację tak, by zapisywała dane do Mastera, a czytała je ze wszystkich końcówek.
Jeżeli chodzi o Redisa, to w tym przykładzie wykorzystujemy replikację złożoną z trzech węzłów. Alternatywnym rozwiązaniem jest wykorzystanie konfiguracji złożonej z dwóch węzłów (także Master-Slave). W obu przypadkach, w celu zapewnienia mechanizmu wykrywania awarii, wymagane są minimum trzy Redis Sentinele — wszystko po to, aby zapewnić przewidywalny i odporny na awarię mechanizm przełączania awaryjnego oraz wytrzymałość grupy Sentineli. Za każdym razem, gdy Sentinel wykryje, że węzeł główny nie odpowiada, będzie on informował o tym zdarzeniu pozostałe Sentinele w grupie. Jednak aby doszło do stwierdzenia, że mistrz uległ awarii, muszą one osiągnąć kworum (ang. quorum), czyli minimalną liczbę Sentineli, która potwierdza, że węzeł główny nie działa, aby móc rozpocząć przełączanie awaryjne (więcej na ten temat w dalszej części artykułu).
Dodanie kolejnych węzłów Redis lub Redis Sentinel pomaga przetrwać sytuację, w której większość z nich ulegnie awarii. Należy pamiętać, że istnieją różne wymagania dotyczące zwłaszcza Sentineli. Jeśli hostujesz je na tych samych serwerach, na których działają procesy Redis, może być konieczne uwzględnienie tych ograniczeń podczas obliczania liczby węzłów do ew. awansowania. Co więcej, wszystkie węzły Redis (w tym Redis Sentinel) powinny być skonfigurowane w ten sam sposób i działać na serwerach o podobnych specyfikacjach.
Możesz zadać pytanie: dobrze, ale po co aż trzy instancje Redis? Ilość węzłów jest bardzo często związana z ilością serwerów, na których działa aplikacja a jeszcze częściej z myśleniem, że im więcej, tym lepiej. Prawda jest taka, że tak naprawdę zależy to od konkretnego przypadku użycia oraz dostępnych zasobów. Nie potrzebujesz trzech węzłów Redis, równie dobrze możesz użyć tylko dwóch. Wykorzystanie większej ilości instancji zwiększa redundancję, ale nie jest to żadnym wymogiem. Może natomiast powodować problemy z wydajnością, np. sieci, ponieważ w przypadku częstych operacji wykorzystanie dużej ilości Redisów jest w stanie wysycić łącza między serwerami, na których są uruchomione procesy Redisa i w konsekwencji sprawić, że serwer nadrzędny będzie przeciążony, czego ostatecznym skutkiem może być obniżenie wydajności aplikacji lub nawet jej niedziałanie. Na przykład mając 10 instancji (1x Master, 9x Slave), które spięte są interfejsem 1Gbps, serwer nadrzędny będzie w stanie przyjąć w przybliżeniu 120MB/s gdzie każdy serwer podrzędny będzie w stanie wygenerować także 120MB/s (czyli ponad 1GB/s do serwera nadrzędnego). Aby wyeliminować to ograniczenie, warto zastanowić się nad wykorzystaniem trybu klastra, który znacznie lepiej rozkłada obciążenia pomiędzy węzłami.
Można też pomyśleć, że większa ilość węzłów to marnowanie zasobów, jednak jeśli potrzebujesz dodatkowej redundancji, są to koszty, które warto ponieść. Co więcej, jeśli uważasz, że posiadanie trzech instancji Redis (i trzech działających Sentineli) jest marnotrawstwem, prawdopodobnie utrzymanie klastra będzie jeszcze bardziej kosztowne, ponieważ wymaga on więcej zasobów. Innym powodem zapewnienia większej ilości serwerów podrzędnych jest podzielenie odczytów (aplikacja musi zapisywać do Mastera, jednak oprócz niego może odczytywać dane z wielu serwerów podrzędnych). Jeśli nie potrzebujesz nadmiarowości i Twoja aplikacja nie jest wymagająca oraz nie ma wygórowanego SLA, równie dobrze możesz uruchomić jedną instancję i traktować ją jako dobrą. W tym artykule zaprezentowałem konfigurację 1x Master, 2x Slave i 3x Sentinel, ponieważ jest ona dosyć często spotykana, a dwa, z taką miałem do czynienia w środowisku klienta, więc chciałem odwzorować sytuację 1:1, aby przedstawić problemy, które musiałem rozwiązać.
Omówienie parametrów konfiguracji #
Wszystkie parametry konfiguracyjne ustawia się z poziomu pliku /etc/redis.conf. Zawartość tego pliku jest używana tylko wtedy, gdy został on dostarczony jako argument dla procesu redis-server dlatego jeśli uruchamiamy Redisa ręcznie bez wskazania pliku konfiguracyjnego, używana jest minimalna konfiguracja domyślna.
Pojawia się tutaj niezwykle istotna rzecz: parametry w tym pliku są w większości trwałe i nie zmieniają się w przypadku restartu danej instancji. Są jednak parametry, które zmieniane są dynamicznie przez proces Redisa oraz Redis Sentinela w zależności od danej sytuacji (np. zmiany serwera nadrzędnego).
Przed przystąpieniem do edycji konfiguracji wykonajmy kilka zadań w celu wprowadzenia pewnego porządku. W pierwszej kolejności utworzymy katalog /etc/redis dla kopii plików konfiguracyjnych oraz skryptów:
mkdir -m 0700 /etc/redis
Następnie utworzymy kopię głównego pliku konfiguracyjnego:
cp /etc/redis.conf /etc/redis/redis.conf.orig
Ostatnim krokiem jest posprzątanie w konfiguracji, czyli na podstawie oryginalnego pliku wyfiltrujemy tylko faktyczne dyrektywy z pominięciem komentarzy:
egrep -v '#|^$' /etc/redis/redis.conf.orig > /etc/redis.conf
Teraz możemy przejść do konfiguracji. Budowa replikacji w zestawieniu 1 serwer pracujący jako Master i 2 serwery pracujące jako Slave jest dosyć częsta, niezwykle prosta i sprowadza się to ustawienia raptem kilku parametrów:
### R1 ###
bind 192.168.10.10 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
replica-priority 1
### R2 ###
bind 192.168.10.20 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
replica-priority 10
replicaof 192.168.10.10 6379
### R3 ###
bind 192.168.10.30 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
masterauth meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
replica-priority 100
replicaof 192.168.10.10 6379
bind i port #
Oba parametry są bardzo intuicyjne i zasada ich działania jest taka sama jak w przypadku konfigurowania innych usług. Opcja bind wiąże instancję Redisa z określonym interfejsem i jest odpowiedzialna za uruchomienie procesu na danym adresie. Domyślna wartość to 127.0.0.1, jeżeli jednak nie zostanie określona lub zostanie ustawiona na 0.0.0.0, Redis będzie nasłuchiwał i zaakceptuje połączenia na wszystkich interfejsach w systemie, czyli z dowolnym adresem. Redis obsługuje także gniazda domeny UNIX, które mogą być używane do nasłuchiwania połączeń przychodzących (domyślnie z nich nie korzysta). Natomiast parametr port określa, na jakim porcie protokołu TCP proces będzie nasłuchiwał połączeń od klientów lub innych instancji (domyślnie jest to port 6379). Co istotne, nie jesteśmy ograniczeniu do uruchomienia jednej instancji Redis na serwerze — możemy utworzyć kilka odseparowanych od siebie procesów, które nasłuchują na tym samym interfejsie na różnych portach.
Użycie adresu pętli zwrotnej służy głównie do podpinania się do usługi za pomocą konsoli i zarządzania danymi instancjami. Druga sprawa jest taka, że zgodnie z ogólnymi zasadami bezpieczeństwa wystawienie usługi na wszystkich interfejsach oraz brak ochrony portu, na którym ona nasłuchuje może mieć duży wpływ na bezpieczeństwo samej usługi jak i całego serwera. Ze względu na charakter Redisa jest to szczególnie istotne, ponieważ atakujący może użyć na przykład polecenia FLUSHALL do usunięcia całego zestawu danych. Jednym z podstawowych rozwiązań tego problemu jest skonfigurowanie filtra pakietów, który będzie kontrolował i w zależności od sytuacji odrzucał połączenia z adresów innych niż te, które przypisane są do konkretnych węzłów.
W prezentowanej konfiguracji Redis będzie nasłuchiwał na dwóch adresach, tj. 192.168.10.x (podane w konfiguracji) i 127.0.0.1 oraz na domyślnym porcie 6379. Aby wyciągnąć aktualną wartość parametrów, wykonujemy:
### R1 ###
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "192.168.10.10 127.0.0.1"
127.0.0.1:6379> CONFIG GET port
1) "port"
2) "6379"
### R2 ###
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "192.168.10.20 127.0.0.1"
127.0.0.1:6379> CONFIG GET port
1) "port"
2) "6379"
### R3 ###
127.0.0.1:6379> CONFIG GET bind
1) "bind"
2) "192.168.10.30 127.0.0.1"
127.0.0.1:6379> CONFIG GET port
1) "port"
2) "6379"
requirepass i masterauth #
Redis w starszych wersjach (zmieniło się to dopiero w wersji 6.x, patrz: ACL) nie implementuje złożonej warstwy kontroli dostępu (brak użytkowników i przypisanych do nich list ACL czy poziomów dostępu), natomiast zapewnia bardzo podstawowy mechanizm uwierzytelniania, który jest domyślnie włączony. Oznacza to tyle, że zapytania od nieuwierzytelnionych klientów będą odrzucane, jednak klient może się uwierzytelnić, wysyłając polecenie AUTH, po którym następuje hasło, co zabezpiecza w pewien sposób wykonanie niezaufanego kodu.
Polecenie
AUTH, podobnie jak każde inne polecenie Redisa, jest wysyłane w postaci niezaszyfrowanej, więc nie chroni przed atakującym, który ma wystarczający dostęp do sieci, aby przeprowadzić podsłuchiwanie. Mimo tych ograniczeń jest to skuteczna warstwa zabezpieczeń przed oczywistym błędem pozostawiania niezabezpieczonych instancji Redis zwłaszcza wystawionej publicznie. Redis ma jednak zaimplementowaną (opcjonalną) obsługę TLS na wszystkich poziomach komunikacji, w tym w połączeń od klientów czy połączeń związanych z replikacją.
Analizując przykładowe konfiguracje, spotkałeś się zapewne z zaleceniami, aby ustawione hasło było naprawdę długie. Możesz zadać pytanie dlaczego? 16 znakowa fraza nie wystarczy? Dokumentacja wyjaśnia to w następujący sposób:
It should be long enough to prevent brute force attacks for two reasons:
▪ Redis is very fast at serving queries. Many passwords per second can be tested by an external client.
▪ The Redis password is stored inside the redis.conf file and inside the client configuration, so it does not need to be remembered by the system administrator, and thus it can be very long.
Dodatkowo jeśli zerkniesz do konfiguracji, napotkasz następujące ostrzeżenie:
Warning: since Redis is pretty fast an outside user can try up to 150k passwords per second against a good box. This means that you should use a very strong password otherwise it will be very easy to break.
Widzimy, że przeprowadzenie enumeracji w Redisie pozwala przetestować wiele haseł na sekundę, stąd odpowiednia długość jest kluczowa do zapewnienia podstawowego bezpieczeństwa.
Parametr requirepass ustawia hasło i wymaga od klientów wydania komendy AUTH <PASSWORD> przed przetworzeniem jakichkolwiek innych poleceń. Natomiast parametr masterauth dodaje uwierzytelnianie w węzłach repliki. Oba parametry są ze sobą powiązane, tzn. jeśli Master ma hasło za pośrednictwem requirepass, skonfigurowanie repliki do używania tego hasła we wszystkich operacjach synchronizacji jest trywialne i sprowadza się do ustawienia tego samego hasła w parametrze masterauth.
W naszej konfiguracji widzisz, że oba parametry ustawione są na każdym węźle, w tym na instancji nadrzędnej (pracującej jako Master). Takie ustawienie jest bardzo istotne, ponieważ mimo tego, że w początkowej konfiguracji określamy, kto ma być mistrzem, a kto podwładnym, podczas ewentualnego promowania nowego Mastera i powrotu starego, nie mógłby się on połączyć z pozostałymi członkami (już jako Slave) i wymieniać z nimi komunikatów. Inna sprawa jest taka, że ustawienie w danej replice tylko dyrektywy masterauth, pozwoli na wykonanie operacji odczytu przez nieuwierzytelnionych klientów.
Ciekawostka: hasło powinno być odpowiednie długie jednak nie za długie, tzn. limit hasła został określony na 512 znaków i zdefiniowany jako makro w pliku src/server.h:
#define CONFIG_AUTHPASS_MAX_LEN 512
Natomiast weryfikacja długości odbywa się z poziomu pliku src/config.c:
else if (!strcasecmp(argv[0],"requirepass") && argc == 2) {
if (strlen(argv[1]) > CONFIG_AUTHPASS_MAX_LEN) {
err = "Password is longer than CONFIG_AUTHPASS_MAX_LEN";
goto loaderr;
}
Niezwykle istotną rzeczą jest to, że podczas tworzenia hasła należy uważać na znaki specjalne oraz to, czy hasło zaczyna się i kończy znakiem cudzysłowu (chyba że nie umieszczamy hasła pomiędzy tymi znakami). Mechanizmy weryfikacji hasła interpretują określoną sekwencję znaków, na przykład:
- pojedyncze i podwójne cudzysłowy
- \x jako cyfry szesnastkowe
- znaki specjalne, takie jak \n, \r, \t, \b, \a
Jeżeli ustawione hasło rozpoczyna się np. znakiem pojedynczego cudzysłowu, ale się nim nie kończy (lub na odwrót) analiza hasła nie powiedzie się i nastąpi najprawdopodobniej błąd skutkujący zrzutem pamięci. Aby zapobiec niepotrzebnym błędom, hasło można wygenerować w ten sposób:
pwgen -s -1 64
Tak jak powiedziałem na wstępie, Redis nie implementuje żadnej solidnej warstwy zabezpieczeń ani nie dostarcza bardziej konserwatywnej konfiguracji domyślnej, stąd ustawienie obu parametrów jest kluczowe w celu zachowania bardzo podstawowego poziomu bezpieczeństwa.
W prezentowanej konfiguracji zostało wygenerowane hasło o długości 40 znaków i ustawione jako wartość obu dyrektyw. Aby wyciągnąć aktualną wartość obu parametrów, wykonujemy:
127.0.0.1:6379> CONFIG GET requirepass
1) "requirepass"
2) "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh"
127.0.0.1:6379> CONFIG GET masterauth
1) "masterauth"
2) "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
Możliwość autoryzacji możemy również przeprowadzić i przetestować telnetując się na odpowiednie gniazdo, na którym nasłuchuje Redis:
telnet 127.0.0.1 6379
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
echo "Hey Redis! AUTH is required?"
-NOAUTH Authentication required.
quit
+OK
Connection closed by foreign host.
telnet 127.0.0.1 6379
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
AUTH <password>
+OK
ping
+PONG
quit
+OK
Connection closed by foreign host.
replica-priority #
Ta opcja (w wersji Redis 5 zastąpiła poprzedni parametr slave-priority) jest związana i używana przez Redis Sentinel i pozwala określić, która z instancji pracująca jako Slave zostanie w pierwszej kolejności wypromowana na węzeł główny (Master), pod warunkiem, że obecny Master uległ awarii. Oznacza to tyle, że Sentinel używa tego parametru w celu wybrania instancji podrzędnej spośród tych, które mogą zostać użyte do przełączenia awaryjnego instancji głównej. Domyślna wartość równa jest 100.
Sentinel preferuje repliki o wyższym priorytecie, co oznacza, że niska wartość jest lepsza (niższa liczba = wyższy priorytet) i to replika o wyższym priorytecie zostanie awansowana na mistrza. Na przykład jeśli istnieją trzy repliki z priorytetami 15, 11, 18, Redis Sentinel podczas przełączania wybierz węzeł z priorytetem 11, czyli najwyższym.
Domyślna konfiguracja podaje przykład ustawienia odpowiednich wartości. Jeśli węzeł podrzędny R2 znajduje się w tym samym centrum danych gdzie Master, a inny węzeł podrzędny R3 w całkowicie innym centrum danych, można ustawić R2 z priorytetem 10 i R3 z priorytetem 100, ponieważ gdy Master ulegnie awarii a oba R2 i R3 są dostępne, preferowany będzie R2, czyli ten będący bliżej.
Istnieje też specjalny priorytet równy 0, który zapobiega awansowaniu węzła do roli Master, co oznacza, że węzeł podrzędny z ustawionym takim priorytetem nigdy nie zostanie wypromowany do roli węzła nadrzędnego. Jednak replika skonfigurowana w ten sposób będzie nadal rekonfigurowana przez Sentinele w celu replikacji z nowym serwerem głównym po przełączeniu awaryjnym, a jedyną różnicą jest to, że sama nigdy nie stanie się główną. Natomiast jeśli priorytet jest taki sam na każdym z węzłów, sprawdzanych jest kilka dodatkowych warunków, w tym przesunięcie replikacji przetwarzane przez daną replikę, dzięki czemu wybierana jest replika, która otrzymała więcej danych z serwera głównego. Jeżeli ten warunek nie jest spełniony, poddawane są ocenie inne parametry (tj. leksykograficznie mniejszy RunID), jednak każdy z nich minimalizuje losowość, co oznacza, że algorytm wyboru repliki, która będzie awansowana na mistrza, jest deterministyczny.
Widzimy, że istnieje tak naprawdę kilka warunków do spełnienia przed dokonaniem ostatecznego wyboru a priorytety mogą być tylko jednym z nich. Uważam natomiast, że priorytet powinien być ustawiony przez administratora dla każdego węzła i powinien być wartością różną tak aby wybrany węzeł stał się instancją nadrzędną na podstawie zamierzonego i przewidywalnego algorytmu.
Kolejny przykład. Mamy konfigurację złożoną z trzech węzłów, Master (R1) o priorytecie 1, i dwie repliki (R2 i R3) o priorytetach kolejno 10 i 100. Kiedy obecny Master ulega awarii, Redis Sentinel wypromuje replikę o priorytecie 10. Jeżeli stary mistrz, o priorytecie 1, powróci do trybu online i ponownie podepnie się do grupy Redisów, to nie odzyska swojego starego statusu — Redis Sentinel nie dokona ponownego przepięcia. Jest to zamierzone zachowanie, ponieważ chodzi o jak najmniejszą liczbę zmian stanu serwera nadrzędnego. Obecnie nie ma żadnego mechanizmu umożliwiającego powrót do zamierzonego wzorca. Priorytet instancji podrzędnej może wpływać na decyzję Sentinela, gdy Master jest wyłączony, ale nie spowoduje zainicjowania przez niego powrotu po awarii, gdy obecny Master znów będzie online (aby było to zrobione automatycznie, musisz zaimplementować to poza wartownikiem). Gdy nastąpi następne przełączenie awaryjne, w tym konkretnym przykładzie stary Master (teraz Slave) o najniższym priorytecie zostanie ponownie awansowany na węzeł nadrzędny.
W prezentowanej konfiguracji ustawiono następujące wartości na każdym węźle:
### R1 ###
127.0.0.1:6379> CONFIG GET replica-priority
1) "replica-priority"
2) "1"
### R2 ###
127.0.0.1:6379> CONFIG GET replica-priority
1) "replica-priority"
2) "10"
### R3 ###
127.0.0.1:6379> CONFIG GET replica-priority
1) "replica-priority"
2) "100"
replicaof #
Parametr replicaof (w wersji Redis 5 zastąpiła poprzedni parametr slaveof) określa ustawienie repliki i jego wartością jest adres IP oraz port serwera pracującego jako Master. Czyli ustawiając tę opcję w konfiguracji, stwierdzamy, że dana instancja będzie pracować jako Slave. Ponadto, parametr ten ma pierwszeństwo nad replica-priority, który ustawiamy z poziomu pliku redis.conf.
Parametry
replicaofimasterauthto dwie główne opcje, dzięki którym dany serwer jest podrzędny i działa jako replika. Opcjareplicaofokreśla IP i port serwera głównego, natomiastmasterauthdefiniuje poświadczenie dostępu do głównego serwera Redis (hasło, które zdefiniowaliśmy wredis.confserwera głównego w opcjirequirepass).
Parametr ten jest zmieniany automatycznie w zależności od sytuacji i statusu danych węzłów, czyli na przykład wtedy, kiedy dojdzie do zmiany serwera nadrzędnego (podobnie jak parametr sentinel monitor w przypadku Sentinela).
Podpinając się za pomocą redis-cli do danej instancji Redisa, za pomocą polecenia replicaof można zmieniać ustawienia replikacji w locie. Jeśli serwer Redis już działa jako Slave, polecenie SLAVEOF no one wyłączy replikację, zmieniając instancję w serwer nadrzędny. Polecenie to w odpowiedniej postaci, tj. replicaof <ip> <port> spowoduje, że serwer, na którym zostanie ono wykonane, będzie repliką innego serwera nasłuchującego na podanym adresie i porcie. Co istotne, ustawienie tego parametru z konsoli w wersji z adresem i portem nie spowoduje natychmiastowej aktualizacji pliku konfiguracyjnego — po tym musimy zapisać konfigurację za pomocą polecenia CONFIG REWRITE.
Istotne jest także to, że wykonanie polecenia w takiej formie na serwerze nadrzędnym spowoduje, że stanie się on repliką! Po wydanie tego polecenia, w konfiguracji takiej jak przedstawiona w tym artykule, przez chwilę będziemy mieli trzy węzły pracujące jako Slave. Jeżeli wykorzystujemy Redis Sentinel, zaktualizuje on automatycznie wszystkie węzły i wypromuje nowego mistrza, jednak parametr replicaof nie zostanie zaktualizowany w pliku konfiguracyjnym (wciąż musimy to zrobić ręcznie).
Aby przełączyć daną instancję w replikę (Slave) wskazujemy adres IP i port serwera nadrzędnego:
127.0.0.1:6379> REPLICAOF <ip> <port>
OK
Natomiast by przełączyć daną instancję w serwer nadrzędny (Master):
127.0.0.1:6379> SLAVEOF no one
OK
W prezentowanej konfiguracji ustawiono następujące wartości na każdym węźle:
### R1 ###
127.0.0.1:6379> CONFIG GET replicaof
1) "replicaof"
2) ""
### R2 ###
127.0.0.1:6379> CONFIG GET replicaof
1) "replicaof"
2) "192.168.10.10 6379"
### R3 ###
127.0.0.1:6379> CONFIG GET replicaof
1) "replicaof"
2) "192.168.10.10 6379"
protected-mode #
Zgodnie z dokumentacją oraz biorąc pod uwagę pewne braki związane z implementacją mechanizmów bezpieczeństwa, Redis jest przeznaczony do uruchamiania w zaufanych środowiskach i powinien być wykorzystywany przez zaufanych klientów. Oznacza to, że nie jest dobrym pomysłem udostępnianie instancji bezpośrednio w Internecie (nigdy nie powinniśmy tego robić!) lub w środowisku, w którym niezaufani klienci mają bezpośredni dostęp do portu TCP lub gniazda UNIX.
Tryb chroniony ma zabezpieczyć głównie te instancje, które są dostępne z sieci zewnętrznych. W tym trybie Redis odpowiada tylko na zapytania z interfejsów pętli zwrotnej i nie zezwala na połączenia klientom łączącym się z niezaufanych adresów. Tryb ten działa, zwłaszcza jeśli nie określono w konfiguracji adresu nasłuchiwania lub nie ustawiono wymaganego od klientów hasła uwierzytelniania.
Jeśli w konfiguracji Redisa zostanie ustawione hasło lub wyraźnie wskażemy adres nasłuchiwania, tryb chroniony jest automatycznie wyłączony. Widzisz, że ma on na celu zabezpieczenie jedynie nieskonfigurowanych instancji i jest pomijany w przypadku modyfikacji parametrów takich jak requirepass lub bind.
W prezentowanej konfiguracji tryb chroniony jest włączony (jest to ustawienie domyślne, także w przypadku braku dyrektywy protected-mode w konfiguracji) na każdym węźle, jednak zgodnie z powyższym, nie jest brany pod uwagę, ponieważ zostały zmodyfikowane parametry, które go znoszą:
127.0.0.1:6379> CONFIG GET protected-mode
1) "protected-mode"
2) "yes"
replica-read-only #
Parametr ten (w wersji Redis 5 zastąpił poprzedni parametr slave-read-only) odpowiada za działanie replik w trybie tylko do odczytu bądź odczytu i zapisu. Według oficjalnej dokumentacji jednym z powodów włączenia trybu tylko do odczytu jest ochrona instancji podrzędnych (zwłaszcza tych udostępnionych w niezaufanej sieci). Ponadto repliki nie pozwalające na zapisy zwiększają odporność replikacji oraz zapobiegają uszkodzeniu danych (głównie dzięki utrzymywaniu wielu kopii danych). Rozmieszczenie takich replik w wielu rozproszonych lokalizacjach dodatkowo podnosi odporność na awarię.
W tym trybie pracy wszystkie polecenia konfiguracyjne są nadal dostępne, więc wykonanie
CONFIGczyDEBUGnie zwróci żadnego błędu (zostało to zresztą opisane w pliku konfiguracyjnym). Dlatego dobrą praktyką jest wyłączenie niektórych poleceń na serwerach pracujących zwłaszcza jako Slave.
Możesz zapytać, jaki jest sens stosowania replik, które mogą przyjmować operacje zapisu? Dokumentacja podaje przykład przechowywania kluczy lokalnie dla powolnych operacji SET lub ZADD (Sorted Set). Ponadto zapisywanie do takich instancji może być przydatne w przypadku przechowywania niektórych danych efemerycznych (można je jednak łatwo usunąć po ponownej synchronizacji z instancją główną). Oczywiście należy mieć świadomość pewnych problemów przy replikach akceptujących zapisy, tj. różne wartości tych samych kluczy lub problematyczna implementacja po stronie klienta.
Niezwykle ważne wspomnienia jest to, że lokalne zapisy zostaną odrzucone jeśli replika ponownie zsynchronizuje się z instancją główną. Ponowna synchronizacja może zostać wykonana poprzez ręczne wypromowanie repliki za pomocą SLAVEOF no one, a następnie ponowne jej podpięcie do aktualnego mistrza za pomocą SLAVEOF <master> <port>. Może też zostać wykonana z poziomu Sentineli za pomocą SENTINEL failover. Natomiast jeśli dojdzie do sytuacji, że będziesz miał klucz foo o wartości bar na każdej z instancji i dokonasz jej aktualizacji na replice akceptującej zapisy, to w wyniku otrzymasz ten sam klucz o różnych wartościach (czyli możesz uzyskać klucz dwukrotnie lub do N razy dla N węzłów). W takiej sytuacji będziemy mieli niespójność danych. Rozwiązaniem jest albo desynchronizacja, albo ponowne zapisanie klucza z odpowiednią wartością na instancji głównej.
Jeśli instancja główna ulegnie awarii i jej rolę przejmie replika, w której znajdują się lokalne klucze, po jej awansowaniu takie klucze nie zostaną utracone. Jeśli w grupie istnieje jeszcze jedna replika, to po zmianie mistrza nie otrzyma ona danych z nowego mistrza. Ponownie, aby doszło do synchronizacji, należy odłączyć i podłączyć repliki do mistrza, wykonać ręczne przełączanie za pomocą Sentineli lub nadpisać wartości znajdującej się na węźle głównym. Jeżeli stary Master stanie się online, to w ramach synchronizacji otrzyma on lokalne klucze z nowego mistrza, natomiast pozostałe repliki zostanę nienaruszone. Co równie ciekawe, restart repliki akceptującej zapisy nie usunie danych, jeśli włączone zostały zapisy RDB lub AOF. Widzimy, że uruchomienie replik akceptujących zapisy może być niezwykle problematyczne jeśli chodzi o spójność danych, a także ich obsługę po stronie klienta czy aplikacji.
Co ciekawe, ponieważ zapisy replik od wersji 4.x są tylko lokalne, nie są propagowane do replik, które są wpięte do instancji podrzędnych znajdujących się poziom wyżej. Takie repliki zawsze otrzymają strumień replikacji identyczny z tym, który jest wysyłany przez serwer główny najwyższego poziomu do replik bezpośrednio do niego podłączonych.
Dokumentacja wspomina także o problemie wygasania kluczy na instancjach podrzędnych pozwalających na zapisy (problem został rozwiązany w Redis 4.x). Otóż starsze wersje Redisa nie mogły eksmitować kluczy z ustawionym czasem życia. Ustawienie wygasania powodowało jego zniszczenie, jednak był on nadal dodawany do łącznej ilości kluczy, zajmując niepotrzebnie pamięć.
Jeżeli zamierzasz zapisywać do replik, być może powinieneś wdrożyć Redisa pracującego w trybie klastra, dzięki czemu będziesz w stanie kierować zapisy między węzłami.
W prezentowanej konfiguracji ustawiono następującą wartość na każdym węźle:
127.0.0.1:6379> CONFIG GET replica-read-only
1) "replica-read-only"
2) "yes"
logfile i loglevel #
Oba parametry są jasne i oczywiste. Pierwszy z nich określa pełną ścieżkę do pliku z dziennikiem, natomiast drugi ustawia poziom logowania. Drugi z parametrów może przyjąć kilka wartości, które odnoszą się do poziomów logowania (ich szczegółowości), gdzie każdy z nich oznaczany jest w specjalny sposób:
- debug (oznaczenie
.) - loguje najwięcej informacji (przydatne przy debugowaniu, zbędne przy normalnej pracy) - verbose (oznaczenie
-) - loguje nadal wiele informacji jednak mniej niż poprzedni tryb (zbędne przy normalnej pracy) - notice (oznaczenie
*) - loguje najważniejsze informacje (zalecany poziom logowania na produkcji) - warning (oznaczenie
#) - loguje tylko krytyczne informacje
Od wersji 3.x informacje wyjściowe dziennika zawierają dodatkowo rolę danego węzła:
pid:role timestamp loglevel message
Gdzie role przyjmują poniższe wartości:
- M - proces Redis Master
- S - proces Redis Slave
- X - proces Redis Sentinela
- C - pod proces (ang. child) RDB/AOF
W prezentowanej konfiguracji na każdym z węzłów obie dyrektywy mają ustawione poniższe wartości:
127.0.0.1:6379> CONFIG GET logfile
1) "logfile"
2) "/var/log/redis/redis.log"
127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
databases #
Nie wspomniałem o tym na samym początku, a powinienem. Otóż Redis w domyślnej konfiguracji tworzy 16 baz (z zakresu od 0 do 15) wewnątrz jednej instancji, jednak możesz ich utworzyć więcej (lub mniej, w zależności od potrzeb). Każda z takich wewnętrznych baz udostępnia odseparowaną i niezależną od pozostałych przestrzeń kluczy. Dostęp do baz odbywa się za pomocą indeksu, a domyślnym indeksem jest ten o numerze zero (indeks można oczywiście zmieniać na dowolną wartość z wcześniej wymienionego zakresu). Co ważne, jeżeli nie zostanie utworzony żaden klucz, nie zostanie też utworzona żadna baza.
Bazy danych w Redisie to sposób na logiczne partycjonowanie danych i możesz o nich pomyśleć jak o „przestrzeni nazw” lub „przestrzeni kluczy”.
Użycie wielu baz danych w jednej instancji zostało uznane przez głównego autora jako antywzorzec, co zostało zresztą opisane tutaj. Dlatego powinieneś podchodzić do tej funkcji dosyć ostrożnie a alternatywą dla wielu źródeł danych może być uruchomienie kilku instancji (także na tym samym serwerze).
W prezentowanej konfiguracji na każdym z węzłów dyrektywa databases ma taką samą (domyślną) wartość:
127.0.0.1:6379> CONFIG GET databases
1) "databases"
2) "16"
Aby wyświetlić wszystkie dostępne bazy oraz ilość przechowywanych przez nie kluczy:
127.0.0.1:6379> INFO keyspace
# Keyspace
db0:keys=2,expires=0,avg_ttl=0
db1:keys=4,expires=0,avg_ttl=0
db2:keys=1,expires=0,avg_ttl=0
Dwa ostanie parametry oznaczają kolejno ilość kluczy z ustawionym wygasaniem oraz średni czas życia kluczy. Natomiast do przełączania się między bazami służy polecenie SELECT:
127.0.0.1:6379> SELECT 2
OK
127.0.0.1:6379[2]>
Zwróć uwagę na nawiasy zamykające liczbę 2 na końcu ostatniego wiersza. Oznacza to, że przejście do tej bazy danych zakończyło się sukcesem.
save i appendonly #
Redis umożliwia przechowywanie danych na dysku twardym, zapewniając w ten sposób pewien poziom trwałości. Zalet zapisywania danych w nieulotnej pamięci masowej nie trzeba wymieniać. Wyobraź sobie scenariusz, w którym wprowadzasz dane do pamięci, jednak w międzyczasie następuje długotrwała przerwa w zasilaniu, co jest równoznaczne z utratą danych, jeśli nie są one zrzucane na dysk.
Jeżeli chodzi o Redisa, to zapisuje on dane w jednym z następujących przypadków:
- automatyczne zapisy w określonych odstępach czasu
- ręczne wywołanie polecenia
SAVElubBGSAVE - w przypadku kiedy proces jest zamykany
Redis obsługuje kilka możliwości zapisywania, które moim zdaniem powinny być dobrane na podstawie technicznych i biznesowych potrzeby projektu, w których wykorzystujesz tę usługę. Na przykład jedną z technik są tak zwane migawki (ang. snapshots), co oznacza, że Redis będzie robił pełną kopię tego, co jest w pamięci w pewnych momentach czasu (np. co pełną godzinę). W przypadku utraty zasilania między dwoma migawkami utracisz dane z czasu między ostatnią migawką a awarią. Dane mogą być też zapisywane przy każdym zapytaniu, co znacznie zwiększa ich bezpieczeństwo, jednak może znacznie spowolnić działanie danej instancji.
Przed przejściem dalej, wyjaśnijmy jeszcze szybko, czym różnią się wywołania SAVE i BGSAVE. Oba robią to samo, czyli zapisują dane do pliku RDB. Różnią się jednak mechanizmem działania:
-
SAVE - to synchroniczne wywołanie tworzy plik RDB instancji Redis, który zawiera cały zestaw danych w określonym momencie. Jest ono wykonywane natychmiast i uruchamia operację synchroniczną, co oznacza, że główny wątek Redis wykonuje zrzut i blokuje wszystkich klientów do momentu zakończenia tworzenia migawki. Nie jest zalecanym wywołaniem na środowiskach produkcyjnych i powinno się je uruchamiać tylko w szczególnych przypadkach
-
BGSAVE - to asynchroniczne wywołanie jest uruchamiane w tle i tworzy plik RDB instancji Redis, który zawiera cały zestaw danych w określonym momencie. Jest to zalecane wywołanie na środowiskach produkcyjnych, ponieważ przy użyciu procesu potomnego wykonuje zapis danych w tle. Przez cały czas działania migawki obsługa klienta nie jest blokowana, ponieważ jest on obsługiwany przez proces nadrzędny
Co ciekawe, za pomocą tych komend możesz przenieść bazę danych z jednego serwera na inny. W pierwszej kolejności zapisujesz zrzut bazy danych do pliku, wywołując polecenie BGSAVE, następnie zatrzymujesz proces Redisa, aby nie doszło do zapisania nowych danych, kopiujesz plik na inny serwer i na koniec uruchamiasz instancję na nowym serwerze z nowym zestawem danych.
Wyświetlając procesy za pomocą polecenia ps, można przechwycić proces potomny o nazwie redis-rdb-bgsave, który jest tworzony przez główny proces w celu wykonania BGSAVE. Ten proces zapisuje wszystkie dane w pamięci a dzięki mechanizmowi Copy-On-Write (COW) nie musi on używać takiej samej ilości pamięci, jak proces główny. Jednak jego wymagania co do pamięci w czasie wykonania zależą od ilości danych, które aktualnie przechowuje Redis i które zostaną zrzucone:
127.0.0.1:6379> INFO memory
# Memory
used_memory:556760440
used_memory_human:530.97M
used_memory_rss:47964160
used_memory_rss_human:45.74M
used_memory_peak:559213568
used_memory_peak_human:533.31M
total_system_memory:8201064448
total_system_memory_human:7.64G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:0.09
mem_allocator:jemalloc-3.6.0
PID User Command Swap USS PSS RSS
3880 redis /usr/bin/redis-server *:6379 513.0M 904.0K 23.1M 45.7M
25050 redis redis-rdb-bgsave *:6379 15.9M 498.3M 520.4M 542.8M
Jeżeli chodzi o zapisy, to Redis tak naprawdę zapewnia trwałość za pomocą dwóch trybów:
- RDB persistence - wykonuje kompaktowe jednoplikowe migawki zbioru danych od czasu do czasu (jest to tryb domyślny)
- zapewnia łatwe przywracanie danych z kopii zapasowej migawki
- zapewnia szybszy restart procesu podczas ładowania dużych zestawów danych
- plik migawki może być znacznie mniejszy niż w przypadku AOF
- AOF persistence - rejestruje każdą operację zapisu otrzymaną przez serwer, która zostanie odtworzona ponownie podczas uruchamiania serwera, odtwarzając oryginalny zestaw danych
- jest znacznie bardziej trwały, np. przy ustawieniu
fsync()na 1 sekundę tracisz tylko dane z ostatniej sekundy - automatycznie zapisywany w tle, dzięki czemu Redis może nadal obsługiwać klientów
- jest znacznie bardziej trwały, np. przy ustawieniu
Jeżeli przeznaczenie platformy, na której działa Redis, związane jest z danymi przetwarzanymi (np. w czasie rzeczywistym) z maksymalną trwałością, to wymagania przed nią stawiane mogą dyktować zapewnienie ich maksymalnego bezpieczeństwa. Wtedy zalecane jest wykorzystanie obu technik jednocześnie. Mówi o tym dokładnie oficjalna dokumentacja:
The general indication is that you should use both persistence methods if you want a degree of data safety comparable to what PostgreSQL can provide you.
Jeżeli dane są istotne, jednak nie mają wartości krytycznej, tj. akceptujesz kilkuminutową ich utratą w przypadku awarii, możesz po prostu użyć samego trybu RDB. Oficjalna dokumentacja odradza używania tylko trybu AOF ze względu na możliwe błędy w silniku AOF.
Podczas restartu (wymuszonego bądź nie), Redis załaduje dane z plików kopii zapasowych i umieści je w pamięci. W przypadku korzystania zarówno z migawki, jak i trybu AOF, Redis użyje tego drugiego, ponieważ daje on większą gwarancję aktualności danych.
Domyślnie Redis zapisuje migawki (tryb RDB) do pliku binarnego o nazwie dump.rdb. Skondensowana wersja działania migawek wygląda następująco:
- tworzony jest proces potomny za pomocą funkcji
fork()- może zająć dużo czasu, jeśli duży zestaw danych i wolny procesor uniemożliwiają dostęp klienta w międzyczasie
- aktualny zbiór danych jest zapisywany przez proces potomny do tymczasowego pliku RDB
- stary plik RDB jest zastępowany przez nowy
Ten tryb możesz skonfigurować tak, aby zapisywał zestaw danych co N sekund, jeśli doszło co najmniej do M zmian. W domyślnej konfiguracji widzimy takie wpisy:
save 900 1
save 300 10
save 60 10000
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
Oznaczają one, że Redis automatycznie uruchomi BGSAVE i zrzuci dane na dysk co:
- 900 sekund (15 minut), jeśli co najmniej 1 klucz zostanie zmieniony
- 300 sekund (5 minut), jeśli co najmniej 10 kluczy zostanie zmienionych
- 60 sekund (minuta), jeśli co najmniej 10000 kluczy zostanie zmienionych
Widzisz, że opcja zapisywania może zawierać więcej niż jedną zasadę kontrolującą częstotliwość wykonywania migawki RDB. Myślę, że wartości te są optymalne, jednak należy je dostosować w zależności od wymagań. Więc jeśli Twoje instancje wykonują naprawdę ciężką pracę i dochodzi do częstego tworzenia, usuwania czy aktualizacji wielu kluczy, zostanie wygenerowana migawka uruchamiana co minutę. Jeśli zmiany nie są tak częste, uruchomiona zostanie 5-minutowa migawka.
W przypadku, gdy Redis nie może utworzyć migawki danych, zawiesi się i przestanie akceptować nowe zapisy w konsekwencji wyświetlając błąd. Jednym z rozwiązań jest ustawienie parametru
stop-writes-on-bgsave-error no, aby zapobiec niepowodzeniu wszystkich zapisów w przypadku niepowodzenia tworzenia migawek. Jeśli zależy Ci na danych, których używasz, powinieneś najpierw sprawdzić, dlaczegoBGSAVEzawiódł. Wymaga to jednak odpowiedniego monitorowania i alertów o awariach.
Jeżeli wykorzystujesz ten tryb pracy i napotkasz problemy wydajnościowe lub jakiekolwiek błędy, które powtarzane są co 60, 300 lub 900 sekund, to bardzo możliwe, że wąskim gardłem jest właśnie tryb migawki lub generalnie tryby zapisu. Wspominam o tym, ponieważ w przypadku jednego ze środowisk, które miałem okazję kiedyś debugować, problem pojawiał się cyklicznie. Było to spowodowane zmianami, które wykonywane w ciągu 60 sekund były znacznie większe niż 10K kluczy powodując blokowanie procesu Redis i powstawanie opóźnień.
Pozostałe dyrektywy są oczywiste: rdbcompression wprowadza kompresję zapisywanych danych, rdbchecksum dodaje sumę kontrolną, która może być przydatna podczas weryfikowania ładowanych danych, np. po restarcie usługi Redis. Natomiast dbfilename wskazuje plik, do którego będą zapisywane dane.
Jeżeli chodzi o drugi tryb, tj. AOF, nie jest on domyślnie włączony i Redis musi być jawnie skonfigurowany, aby go wykorzystywać. Pamiętaj jednak, że ten tryb najprawdopodobniej spowoduje spadek wydajności, a także znaczne rozrastanie się pliku wynikowego. Za konfigurację tego trybu odpowiadają poniższe dyrektywy:
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
Dyrektywa appendonly odpowiada za obsługę trybu AOF i jeśli zostanie on włączony, spowoduje to, że pliki z danymi będą przechowywały każdą zmianę, która ma miejsce, na końcu takiego pliku. Czyli za każdym razem, gdy wyślesz polecenie do instancji, zostanie ono zapisane w pliku, dzięki czemu możesz wykorzystać taki plik do odbudowania całego zestawu danych.
Po pewnym czasie ten plik może stać się naprawdę duży, ponieważ zawiera całą historię każdego klucza. Jednak Redis przepisuje ten plik co jakiś czas, aby był jak najmniejszy, więc zamiast przechowywać całą historię klucza, zaczyna z jego najnowszym stanem.
Parametr appendfilename jest dosyć prosty do zrozumienia, ponieważ określa on ścieżką do pliku, w którym będą zapisywane dane. Kolejny z parametrów, tj. appendfsync jest niezwykle ciekawy. Określa on, ile razy zostanie wywołana funkcja fsync(), zaprojektowana w celu zapewnienia, że dane z wykonywanych operacji na plikach są w pełni zapisywane na dysku twardym w przypadku awarii systemu lub awarii zasilania. Funkcja ta nie należy do najwydajniejszych i zajmuje trochę czasu — jest to znany problem programistom systemów plików, dlatego starają się zapewnić mniej kosztowne alternatywy.
Funkcja
fsync()wymaga, aby wszystkie dane dla określonego deskryptora pliku zostały przesłane do urządzenia pamięci masowej związanego z plikiem. Funkcja ta nie zostanie zakończona, dopóki system nie zakończy zapisu lub nie zostanie wykryty błąd. Jej działanie zależy oczywiście od danego standardu i może się róznić. Na przykład w standardzie POSIX funkcjafsync()mówi: proszę zapisać dane tego pliku na dysku, natomiast w implementacji GNU/Linux oznacza ona: zapisz wszystkie dane i metadane tego pliku na dysku i nie wracaj, dopóki nie zostanie to zrobione.
Dyrektywa ta może przyjąć jedną z trzech wartości:
no- nie wykorzystuje funkcjifsynci przenosi odpowiedzialność za obsługę zapisów na system operacyjnyeverysec- powoduje wykonaniefsyncco jedną sekundę (co oznacza możliwą utratę danych z ostatniej sekundy), jest to domyślny i dosyć szybki tryb pracy i dorównuje wydajnością migawkomalways- powoduje wykonaniefsyncza każdym razem, gdy wykonywane są polecenia, jest to najwolniejsza metoda jednak najbardziej bezpieczna
W przypadku ustawionych zapisów na dysk mogą pojawić się pewne problemy z wydajnością i opóźnieniami. Oficjalna dokumentacja przedstawia pewne zalecenia z tym związane (uporządkowane od lepszego bezpieczeństwa do lepszego opóźnienia):
- AOF +
fsync alwayspowoduje znaczne spowolnienie i powinien być używany tylko wtedy, gdy wiesz, co robisz - AOF +
fsync everysecjest dobrym kompromisem pomiędzy bezpieczeństwem a wydajnością - AOF +
fsync everysec+no-appendfsync-on-rewrite yesdziała podobnie jak powyższe jednak unika wywołaniafsyncpodczas przepisywania w celu zminimalizowania zapisów na dysk - AOF +
fsync nozapisy zależą od jądra, powoduje bardzo niewielkie zapotrzebowanie na I/O dysku i zapewnia minimalne opóźnienia - RDB zapewnia szerokie spektrum kompromisów w zależności od skonfigurowanych wyzwalaczy zapisu
Podczas korzystania z Redisa jako podstawowego magazynu danych lub gdy wymagana jest maksymalna trwałość, rozważ:
- włączanie tylko trybu AOF
- ograniczenie rozmiaru danych na jednym węźle do <1 GB
- ograniczenie specyfikacji serwera (2 rdzenie, 2 GB pamięci operacyjnej)
- korzystanie z dysku o wysokim standardzie w celu zmniejszenia opóźnień podczas zapisywania RDB i zapisu AOF
Jeżeli zamierzasz łączyć oba tryby, pamiętaj o możliwym występowaniu znacznych opóźnień, zwłaszcza jeśli ilość danych, którą przechowujesz w Redisie jest naprawdę duża. Wtedy np. przy wydaniu polecenia SAVE, może dojść do wysokich skoków I/O pamięci masowej. Inna sprawa jest taka, że przy sporym zapisie i wywołaniu np. 60-sekundowego zrzutu do pliku RDB oraz przy włączonym trybie AOF, będzie dochodzić do opóźnień, ponieważ wszystkie zapisy również zajmują trochę czasu, a każda aktualizacja jest zrzucana na dysk i może czekać na zapisanie do pliku AOF.
Powyższe rozważania są również niezwykle istotne przy skalowaniu liniowym za pomocą klastra. Budując klaster pamiętać należy o odpowiednio dostosowanej ilości węzłów do przechowywanych danych. Oznacza to, że możemy zmniejszyć ilość danych w każdym węźle poprzez zwiększenie rozmiaru klastra. Na przykład zwiększając liczbę węzłów głównych z 4 do 8, zmniejszamy o połowę dane w każdym węźle. Niezwykle ważna jest także konfiguracja sprzętowa serwera. Jeżeli jest zbyt wysoka i ma np. 16GB pamięci operacyjnej przy dużej ilości danych, proces tworzenia migawki będzie bardzo powolny, nawet jeśli rozmiar danych jest mniejszy niż 1GB! Może on również zostać przerwany przez mechanizm OOM Killer (więcej poczytasz w Redis process was killed by OS, Is there a bug?). Aby rozwiązać ten problem zaleca się posiadanie maksymalnie 2GB pamięci na każdym węźle.
Jeśli napotkasz jakiekolwiek problemy z zapisami w pierwszej kolejności zerknij na wyjście polecenia INFO persistence, które może wyglądać tak:
127.0.0.1:6379> INFO persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1602264410
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:262144
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
Natomiast jeśli zajdzie potrzeba ręcznego zapisu i tymczasowej zmiany lokalizacji (co może być niekiedy bardzo przydatne):
127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/var/lib/redis"
127.0.0.1:6379> CONFIG SET dir "/path/to/dir"
127.0.0.1:6379> BGSAVE
127.0.0.1:6379> CONFIG SET dir "/var/lib/redis"
Może się jednak zdarzyć, że aplikacja jest skonstruowana tak, że przechowywane dane w Redisie nie są krytyczne. Jeżeli akceptujesz utratę wszystkich danych w przypadku ewentualnych restartów czy awarii, możesz kompletnie wyłączyć zapisy do plików na dysku twardym. Może to delikatnie poprawić wydajność i przydaje się w instalacjach, gdzie dane są traktowane jako faktycznie ulotne, a ich strata nie spowoduje wielkiej katastrofy (czyli np. wtedy kiedy Redis działa jako pamięć podręczna). Aby wyłączyć zapisy, należy ustawić następujące opcje:
# save 900 1
# save 300 10
# save 60 10000
save ""
appendonly no
Przed wprowadzeniem tego ustawienia proponuję wykonać testy I/O, aby jasno stwierdzić, czy skok wydajności jest faktycznie widoczny na danym systemie i jaki ma wpływ na zapisy i odczyty.
Moim zdaniem całkowite wyłączenie zapisu nie jest dobre, ponieważ tryb migawki nie powoduje drastycznego spadku wydajności. Po drugie, załadowanie danych jest czasami przydatne do „podgrzania” pamięci podręcznej, np. po ponownym uruchomieniu, dzięki czemu pamięć podręczna nie będzie pusta, zanim zaczną przychodzić żądania użytkowników. Możesz zadać pytanie, czy to ma faktycznie sens? Jak najbardziej. Pamiętaj, że Redis może przechowywać różne typy danych. Istnieją systemy i procesy, które wymagają pewnych informacji, zanim zaczną odpowiadać na żądania, na przykład platforma handlowa, która wymagałaby danych rynkowych lub informacji o ryzyku itd., zanim będzie mogła przetworzyć żądania użytkowników.
Problem polega jednak na tym, że na początku pamięć podręczna jest pusta, natomiast jej podgrzewanie/wygrzewanie jest ciekawą techniką optymalizacji. Generalnie chodzi o takie przygotowanie pamięci podręcznej, aby była ona zapełniona już na starcie (stąd termin „podgrzanie”, jak w przypadku rozgrzanego silnika samochodu), zamiast sprawić, aby pierwsze zapytania pomijały cache. Stosowanie tej techniki jest trochę ryzykowane, ponieważ moim zdaniem istnieje kilka wad i rzeczy na które należy szczególnie zwracać uwagę. W przypadku witryn o dużym natężeniu ruchu podgrzewanie pamięci podręcznej nie jest konieczne, ponieważ pojawia się wystarczająca liczba odwiedzających, którzy regularnie będą ją wypełniać. W niektórych przypadkach podgrzewanie pamięci podręcznej może znacznie zwiększyć obciążenie serwera. Poza tym sam proces może być problematyczny i skomplikowany wraz ze wzrostem liczby serwerów buforujących.
Swoją drogą sam autor zwraca uwagę na istotę trwałości danych, niezależnie od przeznaczenia Redisa:
You should care about persistence and replication, two features only available in Redis. Even if your goal is to build a cache it helps that after an upgrade or a reboot your data are [sic] still there.
Kolejna niezwykle ważna uwaga, otóż załóżmy, że już skonfigurowałeś Redisa do korzystania z zapisywania RDB. Po jakimś czasie stwierdzasz, że chcesz włączyć tryb AOF. Nigdy nie modyfikuj konfiguracji, aby włączyć ten tryb, ponieważ po restarcie usługi utracisz wszystkie dane. Pamiętaj, że przy restarcie Redis zawsze odtwarza dane zapisane do pliku AOF. Po ustawieniu appendonly yes i ponownym uruchomieniu zostaną załadowane dane z tego pliku, niezależnie od tego, czy on istnieje, czy nie. Jeśli plik nie istnieje, zostanie utworzony pusty plik, a następnie Redis spróbuje zainicjować bazy danymi właśnie z tego pustego pliku.
Natomiast jeśli używasz Redisa w środowisku wymagającym bardzo dużej ilości zapisów, podczas zapisywania pliku RDB na dysku lub przepisywania dziennika AOF, Redis może zużywać 2x więcej pamięci niż podczas normalnej pracy. Wykorzystywana dodatkowa pamięć jest proporcjonalna do liczby stron pamięci zmodyfikowanych przez zapisy podczas procesu zapisywania, więc bardzo często jest proporcjonalna do liczby kluczy przechowywanych w bazie. Upewnij się, że odpowiednio dobrałeś rozmiar swojej pamięci za pomocą parametru maxmemory, o którym porozmawiamy za chwilę.
Dobrze, a w jaki sposób zweryfikować dane w Redisie i to, czy np. są takie same między kilkoma instancjami? Można np. zatrzymać każdą z nich i porównać sumy kontrolne plików RDP (jeśli wykorzystujesz zapisy). Możesz także skorzystać z ciekawego narzędzia o nazwie redis-rdb-tools. Jest to parser plików RDB i pozwala m.in. na generowanie raportu pamięci danych ze wszystkich baz danych i kluczy, konwertowania zrzutu do formatu JSON czy porównywania dwóch plików zrzutu.
Oto sposób instalacji:
yum install gcc python-devel
pip install --upgrade pip
pip install rdbtools python-lzf
Aby wyświetlić wszystkie klucze i wartości a na końcu wyliczyć sumę kontrolną md5 (lub coś podobnego):
rdb --command json redis/dump.rdb | md5sum
Powyższą komendę można wykonać na każdym z węzłów i porównać wynik między nimi. Jeśli suma jest taka samo to OK, jeśli nie, to może być gdzieś problem. Pamiętaj jednak, że z racji replikacji asynchronicznej, zawsze istnieje pewne okno na utratę danych.
Ostatnia sprawa to kopie zapasowe. Rozdział Backing up Redis data oficjalnej dokumentacji mówi tak:
Redis is very data backup friendly since you can copy RDB files while the database is running: the RDB is never modified once produced, and while it gets produced it uses a temporary name and is renamed into its final destination atomically using rename(2) only when the new snapshot is complete. This means that copying the RDB file is completely safe while the server is running.
Opisuje on także pewne sugestie, które należy mieć na uwadze:
- utwórz zadanie cron na swoim serwerze, tworząc cogodzinne migawki pliku RDB w jednym katalogu i codzienne migawki w innym katalogu
- pamiętaj, aby nazwać migawki informacjami o danych i czasie
- za każdym razem, gdy uruchamiany jest cron, dobrze jest usunąć stare migawki (np. starsze niż 3 miesiące)
- pamiętaj, aby przynajmniej raz dziennie kopiować migawkę RDB poza centrum danych lub przynajmniej poza fizyczną maszynę, na której działa instancja Redis
Do wykonywania kopii możesz wykorzystać narzędzie rdiff-backup:
# 1)
0 0 * * * rdiff-backup --preserve-numerical-ids --no-file-statistics /var/lib/redis /backup/redis
# 2)
@daily rdiff-backup --preserve-numerical-ids --no-file-statistics /var/lib/redis /backup/redis
Ponadto, w przypadku przywracania, warto pamiętać o poniższych zasadach:
- w przypadku baz danych, w których ustawiona jest flaga
appendonly no, możesz wykonać następujące czynności:- zatrzymaj proces Redis, ponieważ nadpisuje bieżący plik RDB przed wyjściem
- skopiuj kopię zapasową pliku RDB do katalogu roboczego (jest to opcja
dirw konfiguracji). Upewnij się, że nazwa pliku kopii zapasowej jest zgodna z opcją konfiguracjidbfilename - uruchom proces Redis
- jeśli chcesz przywrócić plik RDB do bazy danych z włączoną opcją
appendonly yes, powinieneś zrobić to w następujący sposób:- zatrzymaj proces Redis, ponieważ nadpisuje bieżący plik RDB przed wyjściem
- skopiuj kopię zapasową pliku RDB do katalogu roboczego (jest to opcja
dirw konfiguracji). Upewnij się, że nazwa pliku kopii zapasowej jest zgodna z opcją konfiguracjidbfilename - ustaw flagę
appendonly no - uruchom proces Redis
- wykonaj z poziomu konsoli Redis komendę
BGREWRITEAOF, aby utworzyć nowy plik tylko do dopisywania - przywróć flagę
appendonly yes
Jeżeli zajdzie potrzeba, może pozmieniać parametry konfiguracji odpowiedzialne za nazwy plików, tryby zapisu czy katalog roboczy lub na szybko odpalić serwera Redis w następujący sposób:
redis-server --dbfilename mydump001.rdb --dir /data --appendonly no
Przy okazji, jeśli chodzi o tworzenie kopii zapasowej danych przechowywanych w Redisie i ich odtwarzania, zapoznaj się z poniższymi zasobami:
- redis-dump
- How To Back Up and Restore Your Redis Data on Ubuntu 14.04
- How do I move a redis database from one server to another?
Na koniec koniecznie zapoznaj się z oficjalną dokumentacją, która we wpisie Redis Persistence opisuje możliwe tryby zapisu do pamięci trwałej oraz je porównuje. Zerknij także do rozdziału 4.1 Persistence options książki Redis in Action.
maxmemory i maxmemory-policy #
Parametr maxmemory przydaje się w celu ograniczania (ustawienia limitu) rozmiaru pamięci, jaki może zostać przydzielony procesowi Redis (pozwala określić maksymalną ilość pamięci do wykorzystania). Wartością domyślną jest 0, która oznacza nieograniczoną ilość (brak limitu), jaka zostanie przydzielona i najczęściej odpowiada pozostałej pamięci dostępnej w systemie, tj. do czasu wyczerpania się pamięci i w konsekwencji możliwego zabicia procesu. Co ciekawe jest to domyślne zachowanie w przypadku systemów 64-bitowych, podczas gdy systemy 32-bitowe używają niejawnego limitu pamięci wynoszącego 3 GB. Ponadto ustawienie domyślne może być kłopotliwe, jeżeli w systemie istnieje ograniczona/mała ilość pamięci operacyjnej.
Gdy nie ma już żadnych kluczy do usunięcia a w puli pozostały tylko klucze nieulotne, zakładając, że wykorzystanie pamięci będzie kontynuowane i nie nastąpią dalsze eksmisje, Redis odpowie błędem OOM (brak pamięci).
Ustawienie tego limitu (bez podania przyrostka oznacza wartość w bajtach) może być przydatne, jednak niesie za sobą kilka utrudnień, o których należy pamiętać:
- po osiągnięciu limitu pamięci Redis spróbuje usunąć klucze zgodnie z wybraną polityką (patrz parametr
maxmemory-policy) - jeśli Redis nie może usunąć kluczy zgodnie z daną polityką (np. przy ustawionym
noeviction), zacznie odpowiadać błędami na polecenia, takie jakSETczyLPUSH, natomiast będzie odpowiadał poprawnie na polecenia odczytu, takie jakGET - jeśli masz repliki dołączone do instancji nadrzędnej z włączoną funkcją
maxmemory, rozmiar buforów wyjściowych wykorzystywanych przez repliki jest odejmowany od liczby używanej pamięci, aby problemy z siecią lub ponowne synchronizacje nie wywołały pętli, w której klucze są usuwane, co może doprowadzić nawet do całkowitego wyczyszczenia bazy!
Z drugiej strony ustawienie limitu może znacznie przyspieszyć zapisy na dysk w przypadku wykorzystania jednego z trybów wyjaśnionych w poprzednim rozdziale, ponieważ przy dużej ilości pamięci operacyjnej i danych, proces tworzenia migawki będzie bardzo powolny. Ponadto jeśli maxmemory nie jest ustawione, Redis będzie nadal przydzielać pamięć według własnego uznania, a tym samym może (stopniowo) pochłaniać całą wolną pamięć. Dlatego ogólnie zaleca się skonfigurowanie pewnego limitu. Uważam, że lepszym pomysłem na ograniczenie wykorzystania pamięci jest odpowiednie dobranie parametrów serwera oraz rozdzielenie danych na kilka procesów Redisa.
Co istotne, wartość tego parametru może być zmieniana dynamicznie:
127.0.0.1:6379> CONFIG GET maxmemory
1) "maxmemory"
2) "0"
127.0.0.1:6379> CONFIG SET maxmemory 1024M
OK
127.0.0.1:6379> CONFIG rewrite
Natomiast polityka eksmisji (ang. eviction policy) kontrolująca rozmiar pamięci i jej wykorzystanie jest ustawiana z poziomu parametru maxmemory-policy. Zależy ona od kilku czynników (tak naprawdę oba parametry są zależne od nich), tj. systemu operacyjnego, procesora i używanego kompilatora oraz alokatora pamięci (domyślnie jemalloc).
Za każdym razem, gdy zapisujesz jakieś dane, Redis alokuje lub realokuje pamięć za pomocą tzw. alokatora. Domyślym alokatorem jest wspomniany wcześniej
jemalloc, o którym poczytasz tutaj oraz w świetnym artykule Scalable memory allocation using jemalloc. Jest to coś, co inteligentnie przydziela pamięć i optymalizuje wyszukiwanie nowych bloków, opierając się na wyrównaniu przydzielonych fragmentów. Polecam także porównanie kilku dostępnych alokatorów pamięci: Testing Memory Allocators oraz On the Impact of Memory Allocation on High-Performance Query Processing [PDF].
Zasady pozbywania się kluczy dotyczą tylko sytuacji, w której przekroczysz maksymalną ilość pamięci — Redis nie usunie niczego automatycznie, jednak może usunąć klucze, jeśli zabraknie pamięci. Domyślnie Redis jest skonfigurowany do używania takiej ilości pamięci RAM, jaką potrzebuje (dyrektywa maxmemory). Dopóki Redis znajduje się w granicach limitów, klucze wygasają tylko wtedy, gdy powinny wygasnąć (jeśli są to klucze ulotne z ustawionym parametrem EXPIRE). Natomiast gdy zużycie pamięci osiągnie odpowiednią wartość, zacznie obowiązywać zdefiniowana polityka eksmisji. Jeśli pamięć jest pełna, uruchamia się algorytm LRU (ang. Least Recently Used), usuwający klucze według określonych zasad, a to, w jaki sposób ten algorytm będzie działał, zależy właśnie od odpowiedniej polityki.
Redis może zarządzać pamięcią na różne sposoby. Wartością domyślną tego parametru jest wspomniana już polityka noeviction, która nie usuwa niczego i zwraca błędy w przypadku operacji zapisu. Może się wydawać, że taka sytuacja jest niepożądana, jednak nie jest ona wcale taka zła, ponieważ w przypadku danych krytycznych jedynym wyborem jest odrzucenie zapisywania, gdy doszło do przekroczenia limitów pamięci. Istnieje też możliwość losowego usuwania kluczy za pomocą allkeys-random, gdy pamięć jest pełna, co może być przydatne, gdy dane traktujemy jednakowo i nie wymagamy wyszukanych algorytmów sprawdzających, które z nich są ważniejsze od innych. Niektóre przypadki używają zasad volatile-*, które wymagają obecności wartości wygaśnięcia (jeśli korzystasz z tego rodzaju zasady eksmisji, upewnij się, że ustawiasz TTL kluczy, które mają wygasnąć) lub zachowują się identycznie jak polityka noeviction. Dokładne informacje o dostępnych politykach znajdziesz w pliku konfiguracyjnym Redisa.
Jeśli dostroisz TTL wystarczająco dobrze i wiesz, ile nowych obiektów jest tworzonych w każdej sekundzie, możesz znacznie zminimalizować nadmierne zużywanie pamięci przez Redisa. Co ważne, jeśli przechowujesz dane nietrwałe, wybierz jedną z zasad eksmisji
volatile-*. Jeśli przechowujesz dane, które nie są ulotne, wybierz jedną z zasadallkeys-*.
Istnieje jeszcze jedna zasada, tj. allkeys-lru, która sprawdza się idealnie w przypadku danych przechowywanych w pamięci podręcznej. W celu zwolnienia pamięci dla gotowych do dodania kluczy, próbuje ona usunąć te, które były najdłużej nieużywane — czyli ofiarą staje się klucz, który był nieużywany przez najdłuższy okres czasu. Dzięki temu Redis jest w stanie samodzielnie zarządzać eksmisją kluczy, a powyższa polityka jest rekomendowaną w większości przypadków. Przy tej technice istnieje jedna ważna uwaga: w tym wypadku ustawienie wygasania kluczy, może powodować dodatkowe obciążenie pamięci.
Mówi zresztą o tym oficjalna dokumentacja:
It is also worth to note that setting an expire to a key costs memory, so using a policy like allkeys-lru is more memory efficient since there is no need to set an expire for the key to be evicted under memory pressure.
Poniżej znajduje się lista, z krótkim opisem każdej z polityk:
-
noeviction- zwraca błąd, jeśli osiągnięto limit pamięci podczas próby zapisania nowych danych -
volatile-lru- usuwa najmniej używane klucze ze wszystkich kluczy, które mają ustawiony czas ważności -
volatile-ttl- usuwa klucze z najkrótszym czasem pozostałym do wygaśnięcia (TTL) ze wszystkich kluczy, które mają ustawiony czas ważności -
volatile-random- usuwa losowe klucze spośród tych, które mają ustawiony czas ważności -
allkeys-lru- usuwa najmniej używane klucze ze wszystkich kluczy -
allkeys-random- usuwa losowe klucze ze wszystkich kluczy
Oraz prosta tabelka, która pozwala lepiej zrozumieć, od czego zależy i na jakie klucze ma wpływ dana polityka:
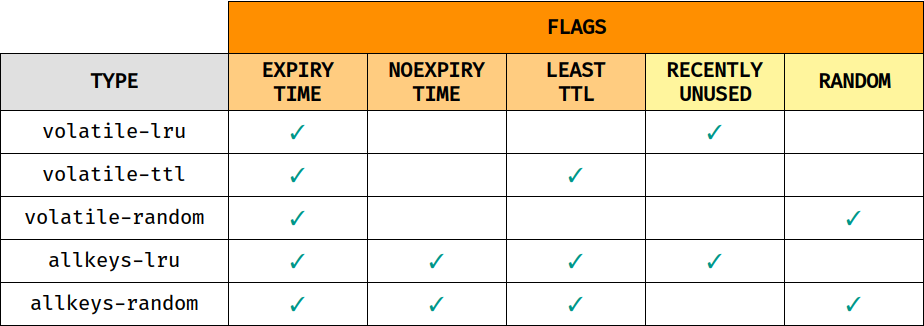
Jak więc Redis usuwa klucze, aby zmniejszyć zużycie pamięci? Otóż Redis używa puli eksmisji (w rzeczywistości specjalnej listy) i zapełnia ją niektórymi losowymi kluczami. Ta pula jest dosyć prosta, ponieważ pierwszy klucz w puli ma najmniejszy czas bezczynności, natomiast ostatni ma maksymalny czas bezczynności. Nadchodzący klucz zostanie dodany w odpowiednim miejscu zgodnie z czasem bezczynności. Redis wybierze najlepszy klucz z końca puli i usunie ten klucz. Ten proces będzie powtarzany do momentu, gdy użycie pamięci będzie poniżej ograniczeń.
Prosty przykład: mamy 100 kluczy z nie zmieniającym się czasem wygasania równym dziesięć dni. Zgodnie z tym każdy z tych kluczy wygaśnie po dziesięciu dniach niezależnie od ustawionych polityk. Przyjmijmy jednak, że osiągnąłeś limity pamięci i chciałbyś dodać nowe klucze. Jeśli ustawisz politykę volatile-lru, to w tym wypadku kandydatami do usunięcia będą najmniej używane klucze ze wszystkich dostępnych. Natomiast jeśli miałbyś 100 kluczy, gdzie 90 z nich miałoby ustawione wygasanie a pozostałe 10 nie, to w przypadku tej polityki kandydatem do usunięcia byłby każdy klucz z tych 90 (usuwany najmniej używany) a pozostałe 10, dla których nie jest liczony TTL, nie byłyby brane pod uwagę. Podobnie dla polityki volatile-ttl jednak tutaj usuwane byłyby te (także z tych 90), które mają najmniejszy czas, który pozostał do wygaśnięcia.
Dodatkowo istnieje możliwość dostrojenia precyzji algorytmu LRU za pomocą parametru maxmemory-samples, który pozwala sterować prędkością i dokładnością danej techniki. Aby zaoszczędzić pamięć, Redis po prostu dodaje 22-bitowe pole do każdego obiektu. Redis może nie wybierać najlepszego kandydata do usunięcia, za nim nie pobierze próbki niewielkiej liczby kluczy. Jeżeli dojdzie do sytuacji, w której będzie potrzeba usunięcia klucza, Redis pobierze N losowych kluczy i szuka tego ze starszym znacznikiem czasu (najdłuższym czasem bezczynności), który stanie się kandydatem do usunięcia. To „N” jest dokładnie wartością powyższego parametru, która jest domyślnie ustawiona na trzy, co jest rozsądnym przybliżeniem LRU na dłuższą metę, ale można uzyskać większą precyzję kosztem nieco dłuższego czasu procesora, zmieniając liczbę kluczy do próbkowania.
Na koniec bardzo istotna rzecz związana z ustawieniem maksymalnego limitu pamięci. Gdy Redis używa więcej danych niż skonfigurowany limit pamięci, będzie zmuszony usunąć jakiś klucz. Bez tego ograniczenia Redis nie będzie działał poprawnie jako pamięć podręczna LRU i zacznie odpowiadać błędami, gdy komendy zużywające pamięć zaczną kończyć się niepowodzeniem. Dlatego ustawiając limit pamięci, zawsze należy pamiętać o dobraniu odpowiedniej polityki, aby poradzić sobie z sytuacją, kiedy musimy odzyskać pamięć.
W prezentowanej konfiguracji na każdym z węzłów dyrektywa maxmemory-policy ma taką samą (domyślną) wartość:
127.0.0.1:6379> CONFIG GET maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
Dokładny opis stosowanych algorytmów i implementacji rozwiązania LRU w Redisie znajduje się w pliku evict.c. Natomiast gorąco zachęcam do przeczytania oficjalnej dokumentacji i rozdziału Using Redis as an LRU cache.
Pierwsze uruchomienie #
Mając skonfigurowane węzły, przystąpmy do ich uruchomienia:
### R1 ###
redis.start
redis.stats
192.168.10.10
PID %CPU %MEM CMD
15043 0.1 0.1 /opt/rh/rh-redis5/root/usr/bin/redis-server 192.168.10.10:6379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replica-priority 1
replica-read-only yes
protected-mode yes
---------------------------------------
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.10.20,port=6379,state=online,offset=7025,lag=1
slave1:ip=192.168.10.30,port=6379,state=online,offset=7025,lag=1
master_replid:c43e6dbead3ef1f309fa7a452b7edb620845027b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7025
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7025
Could not connect to Redis at 127.0.0.1:26379: Connection refused
### R2 ###
redis.start
redis.stats
192.168.10.20
PID %CPU %MEM CMD
22196 0.3 0.1 /opt/rh/rh-redis5/root/usr/bin/redis-server 192.168.10.20:6379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replicaof 192.168.10.10 6379
replica-priority 10
replica-read-only yes
protected-mode yes
---------------------------------------
# Replication
role:slave
master_host:192.168.10.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:7025
slave_priority:10
slave_read_only:1
connected_slaves:0
master_replid:c43e6dbead3ef1f309fa7a452b7edb620845027b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7025
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7025
Could not connect to Redis at 127.0.0.1:26379: Connection refused
### R3 ###
redis.start
redis.stats
192.168.10.30
PID %CPU %MEM CMD
24437 0.3 0.1 /opt/rh/rh-redis5/root/usr/bin/redis-server 192.168.10.30:6379
requirepass "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
masterauth "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
replicaof 192.168.10.10 6379
replica-priority 100
replica-read-only yes
protected-mode yes
---------------------------------------
# Replication
role:slave
master_host:192.168.10.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:7025
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:c43e6dbead3ef1f309fa7a452b7edb620845027b
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7025
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7025
Could not connect to Redis at 127.0.0.1:26379: Connection refused
Powyższe zrzuty są potwierdzeniem, że grupa węzłów została uruchomiona poprawnie, czyli w takiej konfiguracji, jaką sobie założyliśmy: 1x Master (R1) i 2x Slave (R2, R3). Aby zweryfikować czy replikacja na pewno działa poprawnie i czy dane są synchronizowane między wszystkie węzły, wykonajmy na serwerze głównym poniższe komendy:
### R1
127.0.0.1:6379> GET foo
(nil)
127.0.0.1:6379> SET foo bar
OK
Następnie sprawdźmy, czy klucz znajduje się na każdym węźle:
### R1
127.0.0.1:6379> GET foo
"bar"
### R2
127.0.0.1:6379> GET foo
"bar"
### R3
127.0.0.1:6379> GET foo
"bar"
Jeżeli dokonamy utworzenia klucza na którymś z serwerów podrzędnych, otrzymamy błąd jak poniżej:
127.0.0.1:6379> SET xyz bar
(error) READONLY You can't write against a read only slave
Dzieje się tak, ponieważ w konfiguracji został ustawiony parametr replica-read-only, który nie zezwala na zapisy danych do serwerów podrzędnych (jak już wspomniałem wcześniej jest to domyślne zachowanie).
Podsumowanie #
W tej części poznaliśmy czym jest Redis i w jaki sposób zestawić tryb replikacji Master-Slave. W następnej części omówimy usługę Redis Sentinel, przedstawię przykładowe konfiguracje oraz możliwe wytłumaczenia i rozwiązania problemów, które się pojawią.